You might also like
- Euler's Defense of the Bible's Divine OriginDocument6 pagesEuler's Defense of the Bible's Divine Originar_aquinoNo ratings yet
- Journal of The United Nations Programme of Meetings and AgendaDocument36 pagesJournal of The United Nations Programme of Meetings and AgendaMuhammad A'zamNo ratings yet
- Math Fundamental ADocument56 pagesMath Fundamental ALilian Ledesma AngustiaNo ratings yet
- Module Math in The Modern World 1Document187 pagesModule Math in The Modern World 1Princess Erika CanlasNo ratings yet
- Practice Questions Class - X Session - 2021-22 Term 1 Subject-Mathematics (Standard) 041Document19 pagesPractice Questions Class - X Session - 2021-22 Term 1 Subject-Mathematics (Standard) 041Lakshay goyalNo ratings yet
- Algebra 2Document8 pagesAlgebra 2Ejed Daganga Bsee-iiNo ratings yet
- Functional Equations Winter Camp 2012: Lindsey Shorser January 4, 2012Document2 pagesFunctional Equations Winter Camp 2012: Lindsey Shorser January 4, 2012viosirelNo ratings yet
- Student Study Guide and Solutions Chapter 1 FA14 PDFDocument7 pagesStudent Study Guide and Solutions Chapter 1 FA14 PDFJeff CagleNo ratings yet
- History of Math - RomanDocument24 pagesHistory of Math - RomanKristian Lord LeañoNo ratings yet
- TIMSS Assessment Framework Outline (Group 3)Document7 pagesTIMSS Assessment Framework Outline (Group 3)heystobitNo ratings yet
- 4 Gravitaional Constant GDocument64 pages4 Gravitaional Constant Ggomathi_nellaiNo ratings yet
- Math in The Modern WorldDocument6 pagesMath in The Modern WorldMichael JoavanniNo ratings yet
- 4.2 Descriptive Statistics in ExcelDocument26 pages4.2 Descriptive Statistics in ExcelprincessNo ratings yet
- Density ProblemsDocument2 pagesDensity Problemsbeatrizjm9314100% (1)
- Lesson 1: Introduction to SetsDocument11 pagesLesson 1: Introduction to SetsVince Luigi ZepedaNo ratings yet
- Development of The Grit Scale For Children and Adults and Its Relation To Student Efficacy, Test Anxiety, and Academic PerformanceDocument10 pagesDevelopment of The Grit Scale For Children and Adults and Its Relation To Student Efficacy, Test Anxiety, and Academic PerformanceRetno Puspa RiniNo ratings yet
- Mathematical ResilienceDocument5 pagesMathematical Resilienceapi-298719124100% (1)
- Sample Question For Business StatisticsDocument12 pagesSample Question For Business StatisticsLinh ChiNo ratings yet
- Crash Course The Math of Quantum Mechanics PDFDocument6 pagesCrash Course The Math of Quantum Mechanics PDFhuha818No ratings yet
- MTH1020 Unit InformationDocument1 pageMTH1020 Unit InformationmaltykinsNo ratings yet
- Assignment 2: Module Code: HN5001 Module Title: Humanities II Name of The Lecturer: Mr. J.A.D.F.M. JayathilakaDocument9 pagesAssignment 2: Module Code: HN5001 Module Title: Humanities II Name of The Lecturer: Mr. J.A.D.F.M. JayathilakaDimuthu Nuwan AbeysingheNo ratings yet
- 8.1 Coulomb's Law Solutions PDFDocument2 pages8.1 Coulomb's Law Solutions PDFGerryNo ratings yet
- Module 1 To 14Document41 pagesModule 1 To 14Mary Joy CartallaNo ratings yet
- 10 S Mythological Creatures Dichotomous Key LabDocument2 pages10 S Mythological Creatures Dichotomous Key LabSarika BansalNo ratings yet
- Work and Energy 1Document6 pagesWork and Energy 1Rishab DasNo ratings yet
- 1.2. Mathematical Language and SymbolsDocument44 pages1.2. Mathematical Language and SymbolsJhayzelle Anne RoperezNo ratings yet
- Integration ProblemsDocument4 pagesIntegration ProblemsAneesh Amitesh ChandNo ratings yet
- Learning Difficulties in The ClassroomDocument23 pagesLearning Difficulties in The ClassroomDr. Nisanth.P.MNo ratings yet
- Mathematics in the Modern WorldDocument8 pagesMathematics in the Modern WorldRex Jason FrescoNo ratings yet
- Gen Math ExamDocument2 pagesGen Math ExamJeffrey ChanNo ratings yet
- PHYS201 - Lab 5 Coefficient of Friction: Instructional GoalsDocument8 pagesPHYS201 - Lab 5 Coefficient of Friction: Instructional GoalsEmily SilmanNo ratings yet
- LawsDocument40 pagesLawsNaga Rajesh A100% (1)
- The Set of Real Numbers and Its PropertiesDocument29 pagesThe Set of Real Numbers and Its PropertiesSandra Enn BahintingNo ratings yet
- Lab OsmosisDocument7 pagesLab OsmosisAl-masherNo ratings yet
- Intro To Probability and StatisticsDocument147 pagesIntro To Probability and StatisticsDragos-Ronald RugescuNo ratings yet
- Mother Goose Special Science High SchoolDocument7 pagesMother Goose Special Science High Schoolmarie-joseph paul yvech roches marquis de lafayetteNo ratings yet
- Rules For Significant FiguresDocument2 pagesRules For Significant FiguresWilliam BoykeNo ratings yet
- Chapter 4Document100 pagesChapter 4Benjamin LeungNo ratings yet
- C2 Algebra - Remainder and Factor TheoremDocument37 pagesC2 Algebra - Remainder and Factor TheoremDermot ChuckNo ratings yet
- Moderated Mediation of The Relationship of Mathematics Self-Efficacy, GritDocument25 pagesModerated Mediation of The Relationship of Mathematics Self-Efficacy, GritCatherine GauranoNo ratings yet
- TheEffectiveExecutive Peter Drucker NEW PDFDocument5 pagesTheEffectiveExecutive Peter Drucker NEW PDFParvatha SNo ratings yet
- Unit 3 Fourier Analysis Questions and Answers - Sanfoundry PDFDocument5 pagesUnit 3 Fourier Analysis Questions and Answers - Sanfoundry PDFzohaibNo ratings yet
- Mathematics in Nature and its Many ApplicationsDocument9 pagesMathematics in Nature and its Many ApplicationsAaron AbareNo ratings yet
- Proof by exhaustion covers all casesDocument3 pagesProof by exhaustion covers all casesRafih YahyaNo ratings yet
- Ch.2 ProbabilityDocument26 pagesCh.2 ProbabilityGendyNo ratings yet
- Mathematical ProofDocument20 pagesMathematical Proofalecur_alecur3451No ratings yet
- K To 12 Math 7 Curriculum Guide PDFDocument15 pagesK To 12 Math 7 Curriculum Guide PDFEdmar Tan Fabi100% (1)
- 10 Standard Deviation and VarianceDocument5 pages10 Standard Deviation and Varianceapi-299265916No ratings yet
- Solutions-Manual A Readable Introduction To Real MathDocument61 pagesSolutions-Manual A Readable Introduction To Real Mathrobert5918No ratings yet
- Exponential Worksheet1Document3 pagesExponential Worksheet1edren malaguenoNo ratings yet
- Part I Module in Mathematics in The Modern World PDFDocument34 pagesPart I Module in Mathematics in The Modern World PDFRalph QuiambaoNo ratings yet
- The Beginning of Greek MathematicsDocument102 pagesThe Beginning of Greek MathematicsRene Jay-ar Morante SegundoNo ratings yet
- Email:: V=V+At 1 Δx=V T+ At 2 V =V +2AδxDocument3 pagesEmail:: V=V+At 1 Δx=V T+ At 2 V =V +2AδxRaven St. LouisNo ratings yet
- AP Project File Sum of Terms and Geometric ProgressionsDocument5 pagesAP Project File Sum of Terms and Geometric ProgressionsshwetnshanuNo ratings yet
- Integration Problems With SolutionDocument1 pageIntegration Problems With SolutionAneesh Amitesh ChandNo ratings yet
- Graphic Organizer - Venn Diagram ActivityDocument2 pagesGraphic Organizer - Venn Diagram ActivityDevina BranzuelaNo ratings yet
- Putnam Exam Calculus ProblemsDocument9 pagesPutnam Exam Calculus ProblemstadkarNo ratings yet
- Advanced Stat Day 1Document48 pagesAdvanced Stat Day 1Marry PolerNo ratings yet
- Symmetries and Laplacians: Introduction to Harmonic Analysis, Group Representations and ApplicationsFrom EverandSymmetries and Laplacians: Introduction to Harmonic Analysis, Group Representations and ApplicationsNo ratings yet
- Statistical Distributions, Hypothesis Testing Formulas & ConceptsDocument8 pagesStatistical Distributions, Hypothesis Testing Formulas & ConceptsMuhammad AzamNo ratings yet
- Reinventing The Automobile M ItDocument54 pagesReinventing The Automobile M ItHéctor Flores100% (1)
- How The Internet WorksDocument25 pagesHow The Internet Worksdan629No ratings yet
- Jackman RegressionmodelsforcountdataDocument25 pagesJackman RegressionmodelsforcountdataHéctor FloresNo ratings yet
- How Regions Grow: MARCH 2009Document8 pagesHow Regions Grow: MARCH 2009Héctor FloresNo ratings yet
- ReadmeDocument2 pagesReadmeHéctor FloresNo ratings yet
- W 21171Document32 pagesW 21171hectorcflores1No ratings yet
- Lse Sled Mexico PaperDocument47 pagesLse Sled Mexico PaperHéctor FloresNo ratings yet
- LATEXDocument171 pagesLATEXkkk100% (1)
- Double IntegralDocument15 pagesDouble IntegralRaajeev Dobee100% (1)
- Probability Cheatsheet 140718Document7 pagesProbability Cheatsheet 140718Mohit Agrawal100% (1)
- Smil 2005Document37 pagesSmil 2005Héctor FloresNo ratings yet
- Linalg Notes BXCDocument28 pagesLinalg Notes BXCHéctor FloresNo ratings yet
- Fall 2014 Lecture 1 NotesDocument16 pagesFall 2014 Lecture 1 NotesHéctor FloresNo ratings yet
- Disc2M SolDocument2 pagesDisc2M SolHéctor FloresNo ratings yet
- Write Up Read MeDocument1 pageWrite Up Read MeHéctor FloresNo ratings yet
- MIT (14.32) Spring 2009 J. Angrist Lecture Note 5 Confidence IntervalsDocument2 pagesMIT (14.32) Spring 2009 J. Angrist Lecture Note 5 Confidence IntervalsHéctor FloresNo ratings yet
- Using R For Actuarial ScienceDocument11 pagesUsing R For Actuarial ScienceHéctor FloresNo ratings yet
- 17.804: Quantitative Research Methods IIIDocument9 pages17.804: Quantitative Research Methods IIIHéctor FloresNo ratings yet
- Rec 05Document2 pagesRec 05Héctor FloresNo ratings yet
- BPJ TextBook 3 0 5 PDFDocument543 pagesBPJ TextBook 3 0 5 PDFRobert PetersNo ratings yet
- SpatialEconometrics Icpsr Syllabus withExtendedBibliography 2011Document31 pagesSpatialEconometrics Icpsr Syllabus withExtendedBibliography 2011Héctor FloresNo ratings yet
- Massachusetts Institute of TechnologyDocument5 pagesMassachusetts Institute of TechnologyHéctor FloresNo ratings yet
- Matrixcookbook PDFDocument72 pagesMatrixcookbook PDFeetahaNo ratings yet
- Psy 09 N 04Document2 pagesPsy 09 N 04Héctor FloresNo ratings yet
- Syllabus Gov1008 2014Document5 pagesSyllabus Gov1008 2014Héctor FloresNo ratings yet
- ExLATE Handout JA May2011shortDocument30 pagesExLATE Handout JA May2011shortHéctor FloresNo ratings yet
- Mobility GeoDocument104 pagesMobility GeoHéctor FloresNo ratings yet
- Syl32y14r1.New 1Document5 pagesSyl32y14r1.New 1Héctor FloresNo ratings yet
- MIT (14.32) Spring 2009 J. Angrist Lecture Note 5 Confidence IntervalsDocument2 pagesMIT (14.32) Spring 2009 J. Angrist Lecture Note 5 Confidence IntervalsHéctor FloresNo ratings yet
- Psy 09 N 01Document2 pagesPsy 09 N 01Héctor FloresNo ratings yet
- Bakker Vaneerde Designresearch InpressDocument57 pagesBakker Vaneerde Designresearch InpressScent CemoNo ratings yet
- Contoh Soal Generator DC Penguat Seri Dan ParalelDocument38 pagesContoh Soal Generator DC Penguat Seri Dan ParalelBagoes Fudzian PrimaNo ratings yet
- Building Neural Network Models For Time Series: A Statistical ApproachDocument27 pagesBuilding Neural Network Models For Time Series: A Statistical Approachjuan carlosNo ratings yet
- Guide To The Expression of Uncertainty in MeasurementDocument42 pagesGuide To The Expression of Uncertainty in Measurementcristianmondaca100% (1)
- Hubungan Antara Hospitalisasi Anak Dengan Tingkat Kecemasan Orang TuaDocument4 pagesHubungan Antara Hospitalisasi Anak Dengan Tingkat Kecemasan Orang Tuasn amiliaNo ratings yet
- Finding The Answers To The Research QuestionsDocument13 pagesFinding The Answers To The Research QuestionsTristan BabaylanNo ratings yet
- 2019 Yiss - Econometrics (1) - Seokjoo Andrew ChangDocument3 pages2019 Yiss - Econometrics (1) - Seokjoo Andrew ChangJalona HoNo ratings yet
- Threats To Internal and External ValidityDocument6 pagesThreats To Internal and External ValiditySamir Alam100% (3)
- Research Report On Solid Waste Management PDFDocument87 pagesResearch Report On Solid Waste Management PDFAnonymous OP6R1ZS100% (1)
- Dsoc404 Methodology of Social Research EnglishDocument258 pagesDsoc404 Methodology of Social Research EnglishZahidNo ratings yet
- College of Subic Montessori Subic Bay, Inc: Applied Track Subject SyllabusDocument20 pagesCollege of Subic Montessori Subic Bay, Inc: Applied Track Subject Syllabusmichelle garbinNo ratings yet
- Probablity SamplingDocument11 pagesProbablity SamplingHamza Dawid HamidNo ratings yet
- Atomic Emission SpectrosDocument3 pagesAtomic Emission SpectrosRaj MalhotraNo ratings yet
- Akuntansi RadikalDocument19 pagesAkuntansi RadikalPrayogo P HartoNo ratings yet
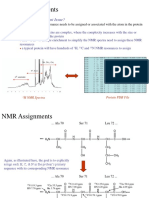
- NMR AssignmentsDocument87 pagesNMR AssignmentsahmedkhidryagoubNo ratings yet
- Module 13-Gage R&R AnalysisDocument32 pagesModule 13-Gage R&R Analysisramasamy_lNo ratings yet
- Factor Analysis PDFDocument57 pagesFactor Analysis PDFsahuek100% (1)
- Statistical Inference, Econometric Analysis and Matrix Algebra. Schipp, Bernhard Krämer, Walter. 2009Document445 pagesStatistical Inference, Econometric Analysis and Matrix Algebra. Schipp, Bernhard Krämer, Walter. 2009José Daniel Rivera MedinaNo ratings yet
- PreliminariesDocument9 pagesPreliminariesErikh James MestidioNo ratings yet
- LEGAL RESEARCH GUIDEDocument21 pagesLEGAL RESEARCH GUIDEPriyesh Kumar100% (1)
- An Introduction To Political Psychology For International Relations ScholarsDocument20 pagesAn Introduction To Political Psychology For International Relations ScholarsReggieNo ratings yet
- Hypothesis-TestingDocument47 pagesHypothesis-TestingJOSE EPHRAIM MAGLAQUENo ratings yet
- Nutrition Essentials A Personal Approach 1st Edition Schiff Solutions ManualDocument19 pagesNutrition Essentials A Personal Approach 1st Edition Schiff Solutions ManualEdwinMyersbnztx100% (36)
- TUGAS Modul 4Document3 pagesTUGAS Modul 4dheanNo ratings yet
- Method Validation: Define, Evaluate, ValidateDocument54 pagesMethod Validation: Define, Evaluate, ValidateLaura GuarguatiNo ratings yet
- De Haas Van Alphen EffectDocument13 pagesDe Haas Van Alphen EffectbillcosbyfatherhoodNo ratings yet
- Pengaruh Pemberian Tambahan Penghasilan Pegawai (TPP) Terhadap Kinerja Pegawai Di Dinas Pendidikan Dan Kebudayaan Kabupaten JenepontoDocument146 pagesPengaruh Pemberian Tambahan Penghasilan Pegawai (TPP) Terhadap Kinerja Pegawai Di Dinas Pendidikan Dan Kebudayaan Kabupaten JenepontoHengky SaputraNo ratings yet
- Construction of Religion as Anthropological CategoryDocument20 pagesConstruction of Religion as Anthropological CategoryCarlos PiñonesNo ratings yet
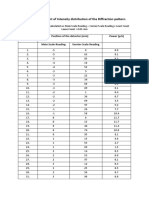
- (A) Measurement of Intensity Distribution of The Diffraction PatternDocument2 pages(A) Measurement of Intensity Distribution of The Diffraction PatternBhupesh YadavNo ratings yet
- Science7 - q1 - Mod1a - Introduction To Scientific Investigation - v3Document23 pagesScience7 - q1 - Mod1a - Introduction To Scientific Investigation - v3Noralyn Ngislawan-Gunnawa89% (19)