You might also like
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Assembly Programming Journal - Issue 4Document49 pagesAssembly Programming Journal - Issue 4lesutsNo ratings yet
- House SDFDocument292 pagesHouse SDFkhatakhunNo ratings yet
- Sea KayakingDocument169 pagesSea Kayakinglesuts100% (4)
- Chemometrics in Enviromental AnalysisDocument393 pagesChemometrics in Enviromental AnalysislesutsNo ratings yet
- The Quick and Dirty Guide To Learning Languages FastDocument177 pagesThe Quick and Dirty Guide To Learning Languages FastCesar Augusto Castellar OrtegaNo ratings yet
- Assembly Programming Journal - Issue 3Document40 pagesAssembly Programming Journal - Issue 3lesuts100% (1)
- Vladimir Vasiliev - Let Every BreathDocument117 pagesVladimir Vasiliev - Let Every BreathMario Quesada97% (34)
- Brooks Mendell Your Hands Secret Weapons 1946Document19 pagesBrooks Mendell Your Hands Secret Weapons 1946cmonBULLSHITNo ratings yet
- (1919) Self Defense For The Individual - Billy SandowDocument22 pages(1919) Self Defense For The Individual - Billy SandowSamurai_Chef100% (4)
- Evolutionary Algorithms For The Determination of Critical DepthDocument6 pagesEvolutionary Algorithms For The Determination of Critical DepthlesutsNo ratings yet
- Assembly Programming Journal - Issue 2Document59 pagesAssembly Programming Journal - Issue 2JustinCaseNo ratings yet
- Assembly Programming Journal - Issue 1Document24 pagesAssembly Programming Journal - Issue 1JustinCaseNo ratings yet
- Modified Akaike Information Criterion (MAIC) For Statistical Model SelectionDocument12 pagesModified Akaike Information Criterion (MAIC) For Statistical Model SelectionlesutsNo ratings yet
- Approximate Moving Least-SquaresDocument10 pagesApproximate Moving Least-SquareslesutsNo ratings yet
- Assembly Programming Journal - Issue 1Document24 pagesAssembly Programming Journal - Issue 1JustinCaseNo ratings yet
- The Identification of Organic Additives in Traditional Lime MortarDocument7 pagesThe Identification of Organic Additives in Traditional Lime MortarlesutsNo ratings yet
- Andrea Kern - Régi Idők Kerti FortélyaiDocument89 pagesAndrea Kern - Régi Idők Kerti Fortélyaitgwh100% (10)
- Microtrac SAADocument2 pagesMicrotrac SAAlesutsNo ratings yet
- Hydraulic Resistance of Artificail Concrete BlocksDocument14 pagesHydraulic Resistance of Artificail Concrete BlockslesutsNo ratings yet
- Kata - The True Essence of BudoDocument16 pagesKata - The True Essence of BudolesutsNo ratings yet
- Far Beyond Defensive TacticsDocument203 pagesFar Beyond Defensive Tacticslesuts100% (4)
- Solving Large Sparse Nonlinear SystemsDocument7 pagesSolving Large Sparse Nonlinear SystemslesutsNo ratings yet
- Assembly Programming Journal - Issue 9Document29 pagesAssembly Programming Journal - Issue 9lesutsNo ratings yet
- Celtic WrestlingDocument183 pagesCeltic Wrestlinglesuts100% (1)
- Assembly Programming Journal - Issue 1Document24 pagesAssembly Programming Journal - Issue 1JustinCaseNo ratings yet
- Chapter 4 Zeolites and Their Potential Uses in AgricultureDocument23 pagesChapter 4 Zeolites and Their Potential Uses in Agriculturelesuts100% (1)
- Assembly Programming Journal - Issue 8Document59 pagesAssembly Programming Journal - Issue 8lesutsNo ratings yet
- Coal Seam Gas OverviewDocument6 pagesCoal Seam Gas OverviewlesutsNo ratings yet
- Design Charts Sewerage PDFDocument29 pagesDesign Charts Sewerage PDFlesutsNo ratings yet
- Design Charts Sewerage PDFDocument29 pagesDesign Charts Sewerage PDFlesutsNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- GSM Multi-Mode Feature DescriptionDocument39 pagesGSM Multi-Mode Feature DescriptionDiyas KazhiyevNo ratings yet
- 01 NumberSystemsDocument49 pages01 NumberSystemsSasankNo ratings yet
- 2023 Prospectus 2Document69 pages2023 Prospectus 2miclau1123No ratings yet
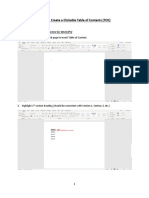
- How To: Create A Clickable Table of Contents (TOC)Document10 pagesHow To: Create A Clickable Table of Contents (TOC)Xuan Mai Nguyen ThiNo ratings yet
- Article 4Document31 pagesArticle 4Abdul OGNo ratings yet
- Safety of High-Rise BuildingsDocument14 pagesSafety of High-Rise BuildingsHananeel Sandhi100% (2)
- JWCh06 PDFDocument23 pagesJWCh06 PDF007featherNo ratings yet
- Final Biomechanics of Edentulous StateDocument114 pagesFinal Biomechanics of Edentulous StateSnigdha SahaNo ratings yet
- FOMRHI Quarterly: Ekna Dal CortivoDocument52 pagesFOMRHI Quarterly: Ekna Dal CortivoGaetano PreviteraNo ratings yet
- SABIC Ethanolamines RDS Global enDocument10 pagesSABIC Ethanolamines RDS Global enmohamedmaher4ever2No ratings yet
- Technical Skills:: Surabhi SrivastavaDocument3 pagesTechnical Skills:: Surabhi SrivastavaPrasad JoshiNo ratings yet
- Denys Vuika - Electron Projects - Build Over 9 Cross-Platform Desktop Applications From Scratch-Packt Publishing (2019)Document429 pagesDenys Vuika - Electron Projects - Build Over 9 Cross-Platform Desktop Applications From Scratch-Packt Publishing (2019)Sarthak PrakashNo ratings yet
- Tps65070X Power Management Ic (Pmic) With Battery Charger, 3 Step-Down Converters, and 2 LdosDocument98 pagesTps65070X Power Management Ic (Pmic) With Battery Charger, 3 Step-Down Converters, and 2 Ldosmok waneNo ratings yet
- Amended ComplaintDocument38 pagesAmended ComplaintDeadspinNo ratings yet
- Instruction/Special Maintenance Instruction (IN/SMI)Document2 pagesInstruction/Special Maintenance Instruction (IN/SMI)ANURAJM44No ratings yet
- Fleck 3150 Downflow: Service ManualDocument40 pagesFleck 3150 Downflow: Service ManualLund2016No ratings yet
- Method StatementDocument11 pagesMethod StatementMohammad Fazal Khan100% (1)
- nrcs143 009445Document4 pagesnrcs143 009445mdsaleemullaNo ratings yet
- Sampling Fundamentals ModifiedDocument45 pagesSampling Fundamentals ModifiedArjun KhoslaNo ratings yet
- Risk Ology ManualDocument2 pagesRisk Ology ManualGregoryNo ratings yet
- Fall Protection ANSIDocument5 pagesFall Protection ANSIsejudavisNo ratings yet
- Nmea Components: NMEA 2000® Signal Supply Cable NMEA 2000® Gauges, Gauge Kits, HarnessesDocument2 pagesNmea Components: NMEA 2000® Signal Supply Cable NMEA 2000® Gauges, Gauge Kits, HarnessesNuty IonutNo ratings yet
- Kunci Jawaban Creative English 3BDocument14 pagesKunci Jawaban Creative English 3BLedjab Fatima67% (3)
- NVH Analysis in AutomobilesDocument30 pagesNVH Analysis in AutomobilesTrishti RastogiNo ratings yet
- Method Statement of Static Equipment ErectionDocument20 pagesMethod Statement of Static Equipment Erectionsarsan nedumkuzhi mani100% (4)
- Itec 3100 Student Response Lesson PlanDocument3 pagesItec 3100 Student Response Lesson Planapi-346174835No ratings yet
- MMDS Indoor/Outdoor Transmitter Manual: Chengdu Tengyue Electronics Co., LTDDocument6 pagesMMDS Indoor/Outdoor Transmitter Manual: Chengdu Tengyue Electronics Co., LTDHenry Jose OlavarrietaNo ratings yet
- Critical Values For The Dickey-Fuller Unit Root T-Test StatisticsDocument1 pageCritical Values For The Dickey-Fuller Unit Root T-Test Statisticswjimenez1938No ratings yet
- Bajaj 100bDocument3 pagesBajaj 100brmlstoreNo ratings yet
- Verificare Bujii IncandescenteDocument1 pageVerificare Bujii IncandescentemihaimartonNo ratings yet