You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Project Report On Online Shopping in JAVADocument75 pagesProject Report On Online Shopping in JAVAManish Yadav83% (35)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Payroll Canadian 1st Edition Dryden Test BankDocument38 pagesPayroll Canadian 1st Edition Dryden Test Bankriaozgas3023100% (14)
- Business Advantage Pers Study Book Intermediate PDFDocument98 pagesBusiness Advantage Pers Study Book Intermediate PDFCool Nigga100% (1)
- Quality Risk ManagementDocument29 pagesQuality Risk ManagementmmmmmNo ratings yet
- MB048 Operations ResearchDocument10 pagesMB048 Operations ResearchKaran SharmaNo ratings yet
- MB048 Operations ResearchDocument10 pagesMB048 Operations ResearchKaran SharmaNo ratings yet
- MB 0045Document6 pagesMB 0045Sandeep KumarNo ratings yet
- Paper ID (A0412)Document2 pagesPaper ID (A0412)Karan SharmaNo ratings yet
- Finance ManagementDocument8 pagesFinance ManagementKaran SharmaNo ratings yet
- Admission Procedure and Counseling Details for Technical InstitutionsDocument5 pagesAdmission Procedure and Counseling Details for Technical InstitutionsKaran SharmaNo ratings yet
- MB0048Document25 pagesMB0048Wasim_Siddiqui_31No ratings yet
- Punjab Technical University Jalandhar Syllabus SchemeDocument35 pagesPunjab Technical University Jalandhar Syllabus Schemesushant100% (1)
- Relationships Beyond Banking: Star House, Plot C-5, "G" Block, Bandra-Kurla Complex, Bandra (East), MumbaiDocument18 pagesRelationships Beyond Banking: Star House, Plot C-5, "G" Block, Bandra-Kurla Complex, Bandra (East), Mumbairockyj47No ratings yet
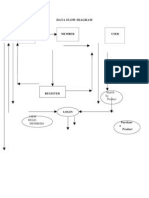
- Data Flow Diagram for Ecommerce WebsiteDocument2 pagesData Flow Diagram for Ecommerce WebsiteKaran SharmaNo ratings yet
- Schedule of Charges General Banking 2022Document18 pagesSchedule of Charges General Banking 2022Shohag MahmudNo ratings yet
- Memento Mori: March/April 2020Document109 pagesMemento Mori: March/April 2020ICCFA StaffNo ratings yet
- VB 2Document11 pagesVB 2Sudhir IkkeNo ratings yet
- Modulus of Subgrade Reaction KsDocument1 pageModulus of Subgrade Reaction KsmohamedabdelalNo ratings yet
- Acknowledgment: George & Also To Our Group Guide Asst. Prof. Simy M Baby, For Their Valuable Guidance and HelpDocument50 pagesAcknowledgment: George & Also To Our Group Guide Asst. Prof. Simy M Baby, For Their Valuable Guidance and HelpKhurram ShahzadNo ratings yet
- Bajaj 100bDocument3 pagesBajaj 100brmlstoreNo ratings yet
- Cantilever Retaining Wall AnalysisDocument7 pagesCantilever Retaining Wall AnalysisChub BokingoNo ratings yet
- WM3000U - WM3000 I: Measuring Bridges For Voltage Transformers and Current TransformersDocument4 pagesWM3000U - WM3000 I: Measuring Bridges For Voltage Transformers and Current TransformersEdgar JimenezNo ratings yet
- Coa - Ofx-8040a (H078K5G018)Document2 pagesCoa - Ofx-8040a (H078K5G018)Jaleel AhmedNo ratings yet
- Renewable and Sustainable Energy ReviewsDocument13 pagesRenewable and Sustainable Energy ReviewsMohammadreza MalekMohamadiNo ratings yet
- Top Machine Learning ToolsDocument9 pagesTop Machine Learning ToolsMaria LavanyaNo ratings yet
- Afar Partnerships Ms. Ellery D. de Leon: True or FalseDocument6 pagesAfar Partnerships Ms. Ellery D. de Leon: True or FalsePat DrezaNo ratings yet
- Financial ManagementDocument21 pagesFinancial ManagementsumanNo ratings yet
- Industry Life Cycle-Plant Based CaseDocument3 pagesIndustry Life Cycle-Plant Based CaseRachelle BrownNo ratings yet
- Courier - Capstone WebApp - Round 3 ReportDocument23 pagesCourier - Capstone WebApp - Round 3 Reportmarmounette26No ratings yet
- Guardplc Certified Function Blocks - Basic Suite: Catalog Number 1753-CfbbasicDocument110 pagesGuardplc Certified Function Blocks - Basic Suite: Catalog Number 1753-CfbbasicTarun BharadwajNo ratings yet
- Unit 13 AminesDocument3 pagesUnit 13 AminesArinath DeepaNo ratings yet
- Tutorial Manual Safi PDFDocument53 pagesTutorial Manual Safi PDFrustamriyadiNo ratings yet
- Exp19 Excel Ch08 HOEAssessment Robert's Flooring InstructionsDocument1 pageExp19 Excel Ch08 HOEAssessment Robert's Flooring InstructionsMuhammad ArslanNo ratings yet
- Market Participants in Securities MarketDocument11 pagesMarket Participants in Securities MarketSandra PhilipNo ratings yet
- Company Profi Le: IHC HytopDocument13 pagesCompany Profi Le: IHC HytopHanzil HakeemNo ratings yet
- Liability WaiverDocument1 pageLiability WaiverTop Flight FitnessNo ratings yet
- Building A Computer AssignmentDocument3 pagesBuilding A Computer AssignmentRajaughn GunterNo ratings yet
- Pass Issuance Receipt: Now You Can Also Buy This Pass On Paytm AppDocument1 pagePass Issuance Receipt: Now You Can Also Buy This Pass On Paytm AppAnoop SharmaNo ratings yet
- Exercise No. 7: AIM: To Prepare STATE CHART DIAGRAM For Weather Forecasting System. Requirements: Hardware InterfacesDocument4 pagesExercise No. 7: AIM: To Prepare STATE CHART DIAGRAM For Weather Forecasting System. Requirements: Hardware InterfacesPriyanshu SinghalNo ratings yet
- Upgrade DB 10.2.0.4 12.1.0Document15 pagesUpgrade DB 10.2.0.4 12.1.0abhishekNo ratings yet
- ProkonDocument57 pagesProkonSelvasatha0% (1)