You might also like
- Module 2Document116 pagesModule 2donyarmstrongNo ratings yet
- Module 1Document104 pagesModule 1donyarmstrongNo ratings yet
- Switching From Windows To Nix or A Newbie To Linux: I TecmintDocument35 pagesSwitching From Windows To Nix or A Newbie To Linux: I TecmintdonyarmstrongNo ratings yet
- Kinux Command DocumentDocument10 pagesKinux Command DocumentdonyarmstrongNo ratings yet
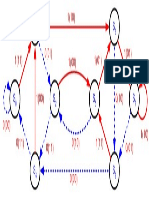
- State Dia6 2 PDFDocument1 pageState Dia6 2 PDFdonyarmstrongNo ratings yet
- PGCETELDocument1 pagePGCETELdonyarmstrongNo ratings yet
- 10EC/TE61: at Least TWO Questions From Each PartDocument2 pages10EC/TE61: at Least TWO Questions From Each PartdonyarmstrongNo ratings yet
- How To Solve A Rubik's Cube (Easy Move Notation) : Easy VPS Cloud HostingDocument9 pagesHow To Solve A Rubik's Cube (Easy Move Notation) : Easy VPS Cloud HostingdonyarmstrongNo ratings yet
- How To Solve The Rubik's CubeDocument3 pagesHow To Solve The Rubik's CubedonyarmstrongNo ratings yet
- Adv Communication Lab ManualDocument63 pagesAdv Communication Lab ManualGopinath B L NaiduNo ratings yet
- State Dia1 PDFDocument1 pageState Dia1 PDFdonyarmstrongNo ratings yet
- State Dia4 PDFDocument1 pageState Dia4 PDFdonyarmstrongNo ratings yet
- PGCETL1Document1 pagePGCETL1donyarmstrongNo ratings yet
- 10EC/TE61: Answer Any FIVE Full Questions, Selecting at Least TWO Questions From Each PartDocument2 pages10EC/TE61: Answer Any FIVE Full Questions, Selecting at Least TWO Questions From Each PartdonyarmstrongNo ratings yet
- 10EC/TE61: at Least TWO Questions From Each PartDocument2 pages10EC/TE61: at Least TWO Questions From Each PartdonyarmstrongNo ratings yet
- Electrical Hazard Awareness Study GuideDocument49 pagesElectrical Hazard Awareness Study GuideKARAM ZAKARIANo ratings yet
- Remedial Class Attendance FormatDocument2 pagesRemedial Class Attendance FormatdonyarmstrongNo ratings yet
- JustDocument1 pageJustdonyarmstrongNo ratings yet
- Cashew Planting TechniquesDocument14 pagesCashew Planting TechniquesdonyarmstrongNo ratings yet
- 09 SpreadSpectrumDocument28 pages09 SpreadSpectrumChandan SasamalNo ratings yet
- GATE-2016 Brochure PDFDocument36 pagesGATE-2016 Brochure PDFPinaki MukherjeeNo ratings yet
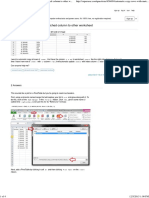
- Microsoft Excel - Automatic Copy Rows With Matched Column To Other Worksheet - Super UserDocument4 pagesMicrosoft Excel - Automatic Copy Rows With Matched Column To Other Worksheet - Super UserdonyarmstrongNo ratings yet
- Digital Ic ListDocument24 pagesDigital Ic ListCosmin PavelNo ratings yet
- EC GATE'14 Paper 03 PDFDocument33 pagesEC GATE'14 Paper 03 PDFTkschandra SekharNo ratings yet
- BCH Codes: APARNA: 4JN11LDS03Document29 pagesBCH Codes: APARNA: 4JN11LDS03donyarmstrongNo ratings yet
- Properties of Hilbert Transform CanonDocument5 pagesProperties of Hilbert Transform CanondonyarmstrongNo ratings yet
- Lecsyll PDFDocument27 pagesLecsyll PDFdonyarmstrongNo ratings yet
- Inside the innards of smart battery firmwareDocument38 pagesInside the innards of smart battery firmwarengt881No ratings yet
- Lenovo P1a42 QSG en Ipig en v1.1 201509Document16 pagesLenovo P1a42 QSG en Ipig en v1.1 201509Lado KranjcevicNo ratings yet
- Audio Signal Classification PDFDocument38 pagesAudio Signal Classification PDFdonyarmstrongNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5782)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- LY-PSKC CW1 Guide For Year 2020Document6 pagesLY-PSKC CW1 Guide For Year 2020Palak ShahNo ratings yet
- Section 1004Document14 pagesSection 1004djbechtelnlNo ratings yet
- Regional Test of A Model For Shallow Landsliding: David R. Montgomery, Kathleen Sullivan and Harvey M. GreenbergDocument15 pagesRegional Test of A Model For Shallow Landsliding: David R. Montgomery, Kathleen Sullivan and Harvey M. GreenbergGeorge MireaNo ratings yet
- Implementation of Victim Compensation Scheme Leaves A Lot To Be DesiredDocument7 pagesImplementation of Victim Compensation Scheme Leaves A Lot To Be DesiredRajivSmithNo ratings yet
- Engleza Bilingv Admitere CL IX Var.1 2012Document2 pagesEngleza Bilingv Admitere CL IX Var.1 2012AaliceMcDonaldNo ratings yet
- Accuracy and Precision Formal ReportDocument6 pagesAccuracy and Precision Formal Reportgarehh60% (5)
- CFA Level 2 NotesDocument21 pagesCFA Level 2 NotesFarhan Tariq100% (2)
- 50 Studies Every Palliative Care Doctor Should Know: Specialty Career Stage SeriesDocument3 pages50 Studies Every Palliative Care Doctor Should Know: Specialty Career Stage SeriesZiggy GonNo ratings yet
- Reflections of The Breast PresentationDocument20 pagesReflections of The Breast PresentationKaren SperlingNo ratings yet
- Co CHM 117 Summer 2018Document11 pagesCo CHM 117 Summer 2018Kamruzzaman ShiponNo ratings yet
- Ryanair Case Study AnalysisDocument5 pagesRyanair Case Study Analysisbinzidd00767% (3)
- FUJITSU 1.2GHz PLL Frequency Synthesizer Data SheetDocument26 pagesFUJITSU 1.2GHz PLL Frequency Synthesizer Data SheetherzvaiNo ratings yet
- CHAPTER VI CREATING BRAND EQUITY - Manansala - RolynDocument16 pagesCHAPTER VI CREATING BRAND EQUITY - Manansala - RolynROLYNNo ratings yet
- Recruitment, Selection, Placement and InductionDocument37 pagesRecruitment, Selection, Placement and InductionPramod KhanvilkarNo ratings yet
- The Province of North Cotabato, Et Al - V - The Government of The Republic of The Philippines, Et Al .Document11 pagesThe Province of North Cotabato, Et Al - V - The Government of The Republic of The Philippines, Et Al .Arbee ArquizaNo ratings yet
- Radio PharmaceuticalsDocument48 pagesRadio PharmaceuticalsKris Joy EbonNo ratings yet
- Evaluate Narrativs Based On How The Author Developed The Element THEMEDocument30 pagesEvaluate Narrativs Based On How The Author Developed The Element THEMEDianArtemiz Mata Valcoba80% (25)
- 18PYB101J ManualDocument38 pages18PYB101J ManualRohit SinghNo ratings yet
- Thesis On Critical Discourse AnalysisDocument225 pagesThesis On Critical Discourse Analysissepisendiri100% (4)
- Preparation of Project ReportDocument18 pagesPreparation of Project ReportshubhraprakashduttaNo ratings yet
- Seeing the Voice, Hearing the Body: The Evolution of Music TheaterDocument10 pagesSeeing the Voice, Hearing the Body: The Evolution of Music TheaterThays W. OliveiraNo ratings yet
- Bread and Pastry TG PDFDocument19 pagesBread and Pastry TG PDFAmpolitoz86% (7)
- Paper Summary - The Quest To Replace Passwords: A Framework For Comparative Evaluation of Web Authentication SchemesDocument1 pagePaper Summary - The Quest To Replace Passwords: A Framework For Comparative Evaluation of Web Authentication SchemesTanmay SrivastavNo ratings yet
- Wilkinson Rogers Formula 2346786Document9 pagesWilkinson Rogers Formula 2346786Raja SooriamurthiNo ratings yet
- Warren Buffett On Stock Market 2001 Fortune ArticleDocument11 pagesWarren Buffett On Stock Market 2001 Fortune ArticleBrian McMorrisNo ratings yet
- Identity, Self and Gender (Document10 pagesIdentity, Self and Gender (hayrunnisa kadriNo ratings yet
- Benedicts and Acetic Acid Urine TestsDocument12 pagesBenedicts and Acetic Acid Urine TestsUALAT STELLA MARIENo ratings yet
- Inventory Management TechniquesDocument11 pagesInventory Management TechniquesSamarth PachhapurNo ratings yet
- A Designer's Guide To The Psychology of Logo ShapesDocument1 pageA Designer's Guide To The Psychology of Logo ShapesFreestileMihaiNo ratings yet
- The Title of EKSAKTA Journal TemplateDocument4 pagesThe Title of EKSAKTA Journal Templatemaisari utamiNo ratings yet