You might also like
- Start Predicting In A World Of Data Science And Predictive AnalysisFrom EverandStart Predicting In A World Of Data Science And Predictive AnalysisNo ratings yet
- Approximate Entropy for Testing Randomness Limiting DistributionDocument16 pagesApproximate Entropy for Testing Randomness Limiting DistributionLeonardo Ochoa RuizNo ratings yet
- Algorithms For Randomness in The Behavioral SciencesDocument16 pagesAlgorithms For Randomness in The Behavioral SciencesRafael AlmeidaNo ratings yet
- A Theorem On Coloring The Lines of A NetworkDocument4 pagesA Theorem On Coloring The Lines of A NetworkcastrojpNo ratings yet
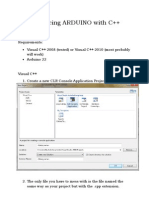
- Interfacing ARDUINO With C++Document4 pagesInterfacing ARDUINO With C++shivamrockzNo ratings yet
- Li & Van Rees - Lower Bounds On Lotto DesignsDocument22 pagesLi & Van Rees - Lower Bounds On Lotto Designsbruno_mérolaNo ratings yet
- Lotto DesignDocument25 pagesLotto DesignClaudioNo ratings yet
- Bayesian methods for testing randomness of lottery drawsDocument34 pagesBayesian methods for testing randomness of lottery drawsHans Marino100% (1)
- Randomness Iris H.Document75 pagesRandomness Iris H.Randomness100% (4)
- LottoDesignsTC MWU 105Document123 pagesLottoDesignsTC MWU 105Antonio Ayrton Pereira da SilvaNo ratings yet
- A Workbook On Implementing L-System Fractals Using PythonDocument9 pagesA Workbook On Implementing L-System Fractals Using PythonShibaji BanerjeeNo ratings yet
- Fractal geometry and superformula to model natural shapesDocument15 pagesFractal geometry and superformula to model natural shapesEndless LoveNo ratings yet
- Game PlayingDocument36 pagesGame PlayingShariq Parwez100% (1)
- Arduino Activity Web Server GuideDocument7 pagesArduino Activity Web Server GuideArdian Ramadita SugaraNo ratings yet
- Hyper Geometric ProbabilityDocument8 pagesHyper Geometric ProbabilitySangita Sangam0% (1)
- Comparison of Id3, Fuzzy Id3 and Probabilistic Id3 Algorithms in The Evaluation of Learning AchievementsDocument5 pagesComparison of Id3, Fuzzy Id3 and Probabilistic Id3 Algorithms in The Evaluation of Learning AchievementsJournal of Computing100% (1)
- Matematika 2 Za FizikeDocument150 pagesMatematika 2 Za FizikePetíčno MlekoNo ratings yet
- Calculus Maple PDFDocument328 pagesCalculus Maple PDFruslanagNo ratings yet
- OnlineTut03 PDFDocument10 pagesOnlineTut03 PDFMohd Nazri SalimNo ratings yet
- Gli Technical Specifications For Random Number Generator TestingDocument2 pagesGli Technical Specifications For Random Number Generator TestingBengabullNo ratings yet
- Guessing a Pop QuizDocument7 pagesGuessing a Pop QuizjaviimbNo ratings yet
- Arch Model and Time-Varying VolatilityDocument17 pagesArch Model and Time-Varying VolatilityJorge Vega RodríguezNo ratings yet
- How To WIN Korea Lotto: Odd-Even Lotto Number TipsDocument5 pagesHow To WIN Korea Lotto: Odd-Even Lotto Number TipsNeeraj ThapaNo ratings yet
- Hidden Markov ModelDocument17 pagesHidden Markov ModelAjayChandrakarNo ratings yet
- Course Notes For Unit 4 of The Udacity Course ST101 Introduction To StatisticsDocument25 pagesCourse Notes For Unit 4 of The Udacity Course ST101 Introduction To StatisticsIain McCullochNo ratings yet
- Fermat and Mersenne NumbersDocument22 pagesFermat and Mersenne NumbersdanrcgNo ratings yet
- Nardl Package: Cointegration Bounds Test Dynamic Multipliers PlotDocument1 pageNardl Package: Cointegration Bounds Test Dynamic Multipliers PlotDaniel CoelhoNo ratings yet
- The Mathematical Relationship Between Heart Rate, Cardiac Output and Pulse Pressure in The Human Systemic VasculatureDocument10 pagesThe Mathematical Relationship Between Heart Rate, Cardiac Output and Pulse Pressure in The Human Systemic Vasculatureian_campbell1624No ratings yet
- Engineering Maths and Stats Course OverviewDocument28 pagesEngineering Maths and Stats Course OverviewBokai ZhouNo ratings yet
- Artificial Neural NetworksDocument14 pagesArtificial Neural NetworksprashantupadhyeNo ratings yet
- Roulette WheelDocument8 pagesRoulette WheelALFafaNo ratings yet
- Stochastic ProcessesDocument31 pagesStochastic ProcessesRafat Al-SroujiNo ratings yet
- Probability-Assignment 1Document4 pagesProbability-Assignment 1ibtihaj aliNo ratings yet
- Racionalna Mehanika Za Studente Matematike - A. Baksa, S. Simic PDFDocument263 pagesRacionalna Mehanika Za Studente Matematike - A. Baksa, S. Simic PDFJovan Srejic100% (1)
- Newtons Method CyclesDocument25 pagesNewtons Method CyclesSamNo ratings yet
- Universiteit Hasselt Concepts in Bayesian Inference Exam June 2015Document8 pagesUniversiteit Hasselt Concepts in Bayesian Inference Exam June 2015Nina MorgensternNo ratings yet
- Institute of Engineering & ManagementDocument18 pagesInstitute of Engineering & ManagementSudhir PatelNo ratings yet
- Trig Cheat Sheet ReducedDocument2 pagesTrig Cheat Sheet ReducedMritunjay KumarNo ratings yet
- Tikz TutorialDocument6 pagesTikz TutorialHugh HghNo ratings yet
- InterpolationDocument13 pagesInterpolationEr Aamir MaqboolNo ratings yet
- The Art of Doing ScienceDocument90 pagesThe Art of Doing SciencemikibenezNo ratings yet
- 10 InverseKinematicsDocument42 pages10 InverseKinematicsAland BravoNo ratings yet
- The Notion of Phenomeno Technique RheinbergerDocument17 pagesThe Notion of Phenomeno Technique Rheinberger1234567juNo ratings yet
- Calculus 1 by Paul FlondorDocument122 pagesCalculus 1 by Paul FlondorJrd CeradoNo ratings yet
- Whos Counting Uniting Numbers and Narratives With Stories From Pop Culture, Puzzles, Politics, and More (John Allen Paulos)Document227 pagesWhos Counting Uniting Numbers and Narratives With Stories From Pop Culture, Puzzles, Politics, and More (John Allen Paulos)titus KisengaNo ratings yet
- Solution 2Document4 pagesSolution 2fra.public0% (1)
- TCS230 Color SensorDocument7 pagesTCS230 Color SensorJoséDavidFiloteoNo ratings yet
- Design and Implementation of A Quantum True Random Number GeneratorDocument24 pagesDesign and Implementation of A Quantum True Random Number Generatormercurio11No ratings yet
- Numerical Methods Formula MaterialDocument6 pagesNumerical Methods Formula MaterialDhilip PrabakaranNo ratings yet
- Conway - On Unsettleable Arithmetical ProblemsDocument8 pagesConway - On Unsettleable Arithmetical ProblemsfreafreafreaNo ratings yet
- Ensemble Average and Time AverageDocument31 pagesEnsemble Average and Time Averageilg1No ratings yet
- Analysis and Design of Algorithms PDFDocument54 pagesAnalysis and Design of Algorithms PDFazmiNo ratings yet
- Wheeled Inverted Pendulum EquationsDocument10 pagesWheeled Inverted Pendulum EquationsMunzir ZafarNo ratings yet
- Arduino SinewaveDocument79 pagesArduino SinewavemerajNo ratings yet
- BBCUserGuide-1 00Document524 pagesBBCUserGuide-1 00manitou1997No ratings yet
- Griffiths & Tenenbaum - Reconciling Intuition and ProbabilityDocument6 pagesGriffiths & Tenenbaum - Reconciling Intuition and ProbabilityMatCult100% (1)
- Kerja Kursus Add MatDocument8 pagesKerja Kursus Add MatSyira SlumberzNo ratings yet
- Add Math Project Work 2016Document12 pagesAdd Math Project Work 2016邓心悦33% (3)
- Probability TheoryDocument6 pagesProbability Theorynatrix029No ratings yet
- Legal Issues For Wikis: The Challenge of User-Generated and Peer-Produced Knowledge, Content and CultureDocument0 pagesLegal Issues For Wikis: The Challenge of User-Generated and Peer-Produced Knowledge, Content and CultureFrank TursackNo ratings yet
- Warnock CamelotDocument6 pagesWarnock CamelotFrank TursackNo ratings yet
- Wikis For Collaborative Software Documentation: 1 Knowledge Work in Software Development CompaniesDocument5 pagesWikis For Collaborative Software Documentation: 1 Knowledge Work in Software Development CompaniesFrank TursackNo ratings yet
- March 2009 en The Global Financial Centres Index 5Document56 pagesMarch 2009 en The Global Financial Centres Index 5api-8832678No ratings yet
- TKD SogiDocument5 pagesTKD SogiFrank TursackNo ratings yet
- Seven Minutes With A PDF Standard - PDF (ISO 32000)Document7 pagesSeven Minutes With A PDF Standard - PDF (ISO 32000)Frank TursackNo ratings yet
- Goju Ryu Stances PDFDocument6 pagesGoju Ryu Stances PDFrawhitesNo ratings yet
- Fighting WC KFDocument0 pagesFighting WC KFFrank TursackNo ratings yet
- ENGL 191 - 2021-22 - Course DescriptionDocument8 pagesENGL 191 - 2021-22 - Course DescriptionAhmed ShreefNo ratings yet
- Grammatical Transformations-Synopsis+Tasks (копія)Document3 pagesGrammatical Transformations-Synopsis+Tasks (копія)Софія Жмут100% (1)
- Winter2023 Psychology 350-102-Ab PastolDocument4 pagesWinter2023 Psychology 350-102-Ab PastolAlex diorNo ratings yet
- Neuroscience of Learning and Development1 PDFDocument18 pagesNeuroscience of Learning and Development1 PDFmemememe100% (1)
- DefinitiveStudent Peer Mentoring Policy Post LTC 07.06.17Document4 pagesDefinitiveStudent Peer Mentoring Policy Post LTC 07.06.17Wisdom PhanganNo ratings yet
- Barriers To Critical ThinkingDocument10 pagesBarriers To Critical ThinkingShahbaz MalikNo ratings yet
- Health2-Second QuarterDocument15 pagesHealth2-Second QuarterPrincess May ItaliaNo ratings yet
- Lecture 1 - IsethuloDocument17 pagesLecture 1 - IsethuloMandisa PreciousNo ratings yet
- DLL - Grades 1 To 12Document6 pagesDLL - Grades 1 To 12Elaine Cachapero AzarconNo ratings yet
- Data Analytics Approach for Sprocket CentralDocument5 pagesData Analytics Approach for Sprocket CentralanmolNo ratings yet
- Types, Structure and Definition of Argumentative EssaysDocument2 pagesTypes, Structure and Definition of Argumentative EssaysRusnawati MahmudNo ratings yet
- Lecture 13 Translation and Terminology Lecture NotesDocument4 pagesLecture 13 Translation and Terminology Lecture NotesIuLy IuLyNo ratings yet
- Subordinating Conjunctions For Complex SentencesDocument2 pagesSubordinating Conjunctions For Complex Sentencesapi-242605102No ratings yet
- Lesson 1 Introduction To Humanities and Nature of ArtsDocument3 pagesLesson 1 Introduction To Humanities and Nature of ArtsRachel VillasisNo ratings yet
- Chapter 2 RRLDocument14 pagesChapter 2 RRLRuvy Caroro Legara DenilaNo ratings yet
- Documentation - Lego HouseDocument2 pagesDocumentation - Lego Houseapi-582199472No ratings yet
- Guidelines For Fs 1Document7 pagesGuidelines For Fs 1Jason Dali-onNo ratings yet
- Mishkin 1983 PDFDocument4 pagesMishkin 1983 PDFamandaNo ratings yet
- ML CourseraDocument10 pagesML CourseraShaheer KhanNo ratings yet
- Year 5 Science Comments. Term 3Document4 pagesYear 5 Science Comments. Term 3Lyaz AntonyNo ratings yet
- Angyris's Single and Double Loop LearningDocument14 pagesAngyris's Single and Double Loop LearningtashapaNo ratings yet
- Develop Effective ParagraphsDocument8 pagesDevelop Effective ParagraphsLA Ricanor100% (1)
- Test Questions LLMD 50 ItemsDocument6 pagesTest Questions LLMD 50 ItemsPamela GalveNo ratings yet
- Critical Reflection on Developing Teaching MaterialsDocument3 pagesCritical Reflection on Developing Teaching MaterialsObjek PelikNo ratings yet
- CreswellQI4e TB06Document6 pagesCreswellQI4e TB06Estef BrozoNo ratings yet
- Human Resource Development Chapter 4Document25 pagesHuman Resource Development Chapter 4Bilawal Shabbir100% (1)
- Difference between ANN CNN RNN Neural NetworksDocument5 pagesDifference between ANN CNN RNN Neural NetworksMuhd YaakubNo ratings yet
- Received PronunciationDocument4 pagesReceived PronunciationKevinNo ratings yet
- Analyzing Cultural Contexts in TextsDocument19 pagesAnalyzing Cultural Contexts in TextsMayflor Asurquin88% (8)
- University of The Philippines Cebu: Student's Signature: - Signature of Thesis AdviserDocument10 pagesUniversity of The Philippines Cebu: Student's Signature: - Signature of Thesis AdviserRodel Cañamo OracionNo ratings yet
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (54)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (12)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- AI Money Machine: Unlock the Secrets to Making Money Online with AIFrom EverandAI Money Machine: Unlock the Secrets to Making Money Online with AINo ratings yet
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- How to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.From EverandHow to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.No ratings yet
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)
- 2084: Artificial Intelligence and the Future of HumanityFrom Everand2084: Artificial Intelligence and the Future of HumanityRating: 4 out of 5 stars4/5 (81)
- The Emperor's New Mind: Concerning Computers, Minds, and the Laws of PhysicsFrom EverandThe Emperor's New Mind: Concerning Computers, Minds, and the Laws of PhysicsRating: 3.5 out of 5 stars3.5/5 (403)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- 100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesFrom Everand100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesNo ratings yet
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- The Digital Mindset: What It Really Takes to Thrive in the Age of Data, Algorithms, and AIFrom EverandThe Digital Mindset: What It Really Takes to Thrive in the Age of Data, Algorithms, and AIRating: 3.5 out of 5 stars3.5/5 (7)
- Killer ChatGPT Prompts: Harness the Power of AI for Success and ProfitFrom EverandKiller ChatGPT Prompts: Harness the Power of AI for Success and ProfitRating: 2 out of 5 stars2/5 (1)
- ChatGPT for Business the Best Artificial Intelligence Applications, Marketing and Tools to Boost Your IncomeFrom EverandChatGPT for Business the Best Artificial Intelligence Applications, Marketing and Tools to Boost Your IncomeNo ratings yet
- System Design Interview: 300 Questions And Answers: Prepare And PassFrom EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassNo ratings yet