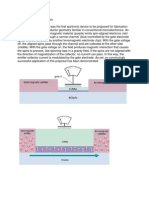
You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Virtue of Exclusivity in The Avant GardeDocument8 pagesVirtue of Exclusivity in The Avant GardeZach WeinerNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Soul SearchingDocument9 pagesSoul SearchingZach WeinerNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- What Are You?Document5 pagesWhat Are You?Zach WeinerNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Rhetoric of Second Life and The Politics of GlobalizationDocument11 pagesThe Rhetoric of Second Life and The Politics of GlobalizationZach WeinerNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Porta by AmbarrukmoDocument4 pagesPorta by AmbarrukmoRika AyuNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Heradesign Brochure 2008Document72 pagesHeradesign Brochure 2008Surinder SinghNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Whatever Happens, Happens For Something Good by MR SmileyDocument133 pagesWhatever Happens, Happens For Something Good by MR SmileyPrateek100% (3)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Datta Das FET ExplanationDocument2 pagesDatta Das FET ExplanationJulie HaydenNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Adeptus Evangelion 2.5 - Operations ManualDocument262 pagesAdeptus Evangelion 2.5 - Operations ManualGhostwheel50% (2)
- Abundance BlocksDocument1 pageAbundance BlockssunnyNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Fajar Secondary Sec 3 E Math EOY 2021Document16 pagesFajar Secondary Sec 3 E Math EOY 2021Jayden ChuaNo ratings yet
- 2021 - Tet Purchase Behavior Report - INFOCUSDocument15 pages2021 - Tet Purchase Behavior Report - INFOCUSGame AccountNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- 5s OfficeDocument10 pages5s OfficeTechie InblueNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Ca2Document8 pagesCa2ChandraNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Physics SyllabusDocument85 pagesPhysics Syllabusalex demskoyNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Quill Vol. LVIII Issue 1 1-12Document12 pagesThe Quill Vol. LVIII Issue 1 1-12Yves Lawrence Ivan OardeNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- DCI-2 Brief Spec-Rev01Document1 pageDCI-2 Brief Spec-Rev01jack allenNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- Product:: Electronic, 2 C #18 STR TC, PE Ins, OS, PVC JKT, CMDocument2 pagesProduct:: Electronic, 2 C #18 STR TC, PE Ins, OS, PVC JKT, CMAnonymous XYAPaxjbYNo ratings yet
- Sample Field Trip ReportDocument6 pagesSample Field Trip ReportBILAL JTTCNo ratings yet
- Ebrosur Silk Town PDFDocument28 pagesEbrosur Silk Town PDFDausNo ratings yet
- Standardization Parameters For Production of Tofu Using WSD-Y-1 MachineDocument6 pagesStandardization Parameters For Production of Tofu Using WSD-Y-1 MachineAdjengIkaWulandariNo ratings yet
- Fund. of EnterpreneurshipDocument31 pagesFund. of EnterpreneurshipVarun LalwaniNo ratings yet
- Sundar KandvalmikiDocument98 pagesSundar Kandvalmikifactree09No ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Applying Value Engineering to Improve Quality and Reduce Costs of Ready-Mixed ConcreteDocument15 pagesApplying Value Engineering to Improve Quality and Reduce Costs of Ready-Mixed ConcreteayyishNo ratings yet
- NitrocelluloseDocument7 pagesNitrocellulosejumpupdnbdjNo ratings yet
- Induction Hardening - Interpretation of Drawing & Testing PDFDocument4 pagesInduction Hardening - Interpretation of Drawing & Testing PDFrajesh DESHMUKHNo ratings yet
- Principle Harmony RhythmDocument16 pagesPrinciple Harmony RhythmRosalinda PanopioNo ratings yet
- Ampersand MenuDocument5 pagesAmpersand MenuJozefNo ratings yet
- Kuffner Final PresentationDocument16 pagesKuffner Final PresentationSamaa GamalNo ratings yet
- NarendraVani KallubaluVKV 2010-11Document144 pagesNarendraVani KallubaluVKV 2010-11Vivekananda Kendra100% (1)
- Gps Vehicle Tracking System ProjectDocument3 pagesGps Vehicle Tracking System ProjectKathrynNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Guidelines On Dissolution Profile Comparison: Udrun ReitagDocument10 pagesGuidelines On Dissolution Profile Comparison: Udrun ReitagRaju GawadeNo ratings yet
- Ch3 XII SolutionsDocument12 pagesCh3 XII SolutionsSaish NaikNo ratings yet
- SSX Diaphragm: Truextent® Replacement Diaphragms For JBL and RADIANDocument2 pagesSSX Diaphragm: Truextent® Replacement Diaphragms For JBL and RADIANIvica IndjinNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)