You might also like
- Biomedical Data Analysis by Supervised Manifold LearningDocument4 pagesBiomedical Data Analysis by Supervised Manifold LearningCarlos López NoriegaNo ratings yet
- F.-M. Schleif, T. Villmann and B. Hammer - Prototype Based Fuzzy Classification in Clinical ProteomicsDocument20 pagesF.-M. Schleif, T. Villmann and B. Hammer - Prototype Based Fuzzy Classification in Clinical ProteomicsGrettszNo ratings yet
- A Review On Classification Based Approaches For STEGanalysis DetectionDocument7 pagesA Review On Classification Based Approaches For STEGanalysis DetectionATSNo ratings yet
- Robust Continuous Clustering: Sohil Atul Shah and Vladlen KoltunDocument6 pagesRobust Continuous Clustering: Sohil Atul Shah and Vladlen KoltunjayjayNo ratings yet
- CHEMOMETRICS and STATISTICS Multivariate Classification Techniques-21-27Document7 pagesCHEMOMETRICS and STATISTICS Multivariate Classification Techniques-21-27Jose GarciaNo ratings yet
- Using SAS For The Design Analysis and Visualization of Complex SurveyDocument15 pagesUsing SAS For The Design Analysis and Visualization of Complex SurveyarijitroyNo ratings yet
- The PLS Method - Partial Least Squares Projections To Latent StructuresDocument44 pagesThe PLS Method - Partial Least Squares Projections To Latent StructuresJessicaNo ratings yet
- Cervigram Image Segmentation Based On Reconstructive Sparse RepresentationsDocument8 pagesCervigram Image Segmentation Based On Reconstructive Sparse RepresentationsPrasanalakshmi BalajiNo ratings yet
- Cluster AnalysisDocument6 pagesCluster AnalysisDeepak BhardwajNo ratings yet
- A Generative Mold For Image Segmentation Based On Tag UnionDocument10 pagesA Generative Mold For Image Segmentation Based On Tag Unionsurendiran123No ratings yet
- Ijatcse 43922020Document6 pagesIjatcse 43922020rod2021No ratings yet
- Multivariate Linear QSPR/QSAR Models: Rigorous Evaluation of Variable Selection For PLSDocument10 pagesMultivariate Linear QSPR/QSAR Models: Rigorous Evaluation of Variable Selection For PLSTiruneh GANo ratings yet
- Smooth Splines Large DataDocument22 pagesSmooth Splines Large DataergoshaunNo ratings yet
- Multidimensional Data AnalysisDocument24 pagesMultidimensional Data AnalysisNovia WidyaNo ratings yet
- Breast Cancer ClassificationDocument18 pagesBreast Cancer ClassificationSatwik Sridhar ReddyNo ratings yet
- Atm 08 16 982Document8 pagesAtm 08 16 982JorgeNo ratings yet
- Multivariate StatisticsDocument6 pagesMultivariate Statisticsbenjamin212No ratings yet
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraNo ratings yet
- Overview and Recent Advances in Partial Least Squares: Lecture Notes in Computer Science November 2005Document19 pagesOverview and Recent Advances in Partial Least Squares: Lecture Notes in Computer Science November 2005Liliana ForzaniNo ratings yet
- Lecture 6: Classifying The Terrestrial Environment Using Optical Earth Observed ImagesDocument16 pagesLecture 6: Classifying The Terrestrial Environment Using Optical Earth Observed ImagesJayesh ShindeNo ratings yet
- Multivariate Statistical Analysis: Prof. DR.: RAFAEL AMARODocument29 pagesMultivariate Statistical Analysis: Prof. DR.: RAFAEL AMAROGenesis Carrillo GranizoNo ratings yet
- Local Rank Analysis for Spectroscopic Image WindowsDocument11 pagesLocal Rank Analysis for Spectroscopic Image WindowsSkroz LudNo ratings yet
- Human Activity ClassificationDocument6 pagesHuman Activity Classificationnikhil singhNo ratings yet
- Det ÐWÞ Det ÐTÞ: R. Kumar, V. Sharma / Trends in Analytical Chemistry 105 (2018) 191 E201 192Document1 pageDet ÐWÞ Det ÐTÞ: R. Kumar, V. Sharma / Trends in Analytical Chemistry 105 (2018) 191 E201 192THE IMAN'S YOUTUBENo ratings yet
- A Novel Level Set Model With Automated Initialization and ControllingDocument9 pagesA Novel Level Set Model With Automated Initialization and ControllingJuan PabloNo ratings yet
- $discretization of Continuous Valued Dimensions in OLAP Data Cubes - 20081117Document11 pages$discretization of Continuous Valued Dimensions in OLAP Data Cubes - 20081117SUNGNo ratings yet
- Datawarehousing and Data MiningDocument119 pagesDatawarehousing and Data MininglakshmiraghujashuNo ratings yet
- HCPC Husson JosseDocument17 pagesHCPC Husson JosseZain AamirNo ratings yet
- A Simple Anomaly Detection For Spectral Imagery Using Co-Occurrence Statistics TechniquesDocument4 pagesA Simple Anomaly Detection For Spectral Imagery Using Co-Occurrence Statistics TechniqueszallpallNo ratings yet
- Analysis&Comparisonof Efficient TechniquesofDocument5 pagesAnalysis&Comparisonof Efficient TechniquesofasthaNo ratings yet
- Rule Extraction in Diagnosis of Vertebral Column DiseaseDocument5 pagesRule Extraction in Diagnosis of Vertebral Column DiseaseEditor IJRITCCNo ratings yet
- CS 231N Final Project Report: Cervical Cancer ScreeningDocument9 pagesCS 231N Final Project Report: Cervical Cancer Screeningshital shermaleNo ratings yet
- Descriptive Data MiningDocument8 pagesDescriptive Data MiningJamila FerrerNo ratings yet
- Kernel Methods in Remote SensingDocument34 pagesKernel Methods in Remote SensingChun F HsuNo ratings yet
- Ijcttjournal V1i1p12Document3 pagesIjcttjournal V1i1p12surendiran123No ratings yet
- Methods For Meta-Analysis and Meta-Regression of PDocument26 pagesMethods For Meta-Analysis and Meta-Regression of PKwame GogomiNo ratings yet
- Domaining by Clustering Multivariate Geostatistical DataDocument12 pagesDomaining by Clustering Multivariate Geostatistical DataKasse VarillasNo ratings yet
- A New Latent Class To Fit Spatial Econometrics Models - 2015 - Procedia EnvironDocument3 pagesA New Latent Class To Fit Spatial Econometrics Models - 2015 - Procedia Environteo cucuNo ratings yet
- CHP 3A10.1007 2F978 3 642 39342 6 - 17 PDFDocument10 pagesCHP 3A10.1007 2F978 3 642 39342 6 - 17 PDFM. Muntasir RahmanNo ratings yet
- An Introduction to Geostatistical AnalysisDocument7 pagesAn Introduction to Geostatistical AnalysisJose RojasNo ratings yet
- Multi Modal Medical Image Fusion Using Weighted Least Squares FilterDocument6 pagesMulti Modal Medical Image Fusion Using Weighted Least Squares FilterInternational Journal of Research in Engineering and TechnologyNo ratings yet
- Fuzzy Image Classification Using Multiresolution Neural Networks With Applications To Remote SensingDocument4 pagesFuzzy Image Classification Using Multiresolution Neural Networks With Applications To Remote SensingidreesgisNo ratings yet
- I Jcs It 2015060141Document5 pagesI Jcs It 2015060141SunilAjmeeraNo ratings yet
- Automatic selection by penalized asymmetric Lq -norm in high-D model with grouped variablesDocument39 pagesAutomatic selection by penalized asymmetric Lq -norm in high-D model with grouped variablesMarcelo Marcy Majstruk CimilloNo ratings yet
- Multi Modal Medical Image Fusion Using Weighted Least Squares FilterDocument6 pagesMulti Modal Medical Image Fusion Using Weighted Least Squares FilterVivek VenugopalNo ratings yet
- PLS-DA for hyperspectral data classificationDocument21 pagesPLS-DA for hyperspectral data classificationJoseNo ratings yet
- Supervised Dimensionality Reduction For Big DataDocument10 pagesSupervised Dimensionality Reduction For Big Datammonique.rizziNo ratings yet
- Vogel 1979Document9 pagesVogel 1979javiera.quirozNo ratings yet
- Sorting Variables by Using Informative Vectors As A Strategy For Feature Selection in Multivariate RegressionDocument17 pagesSorting Variables by Using Informative Vectors As A Strategy For Feature Selection in Multivariate RegressionALDO JAVIER GUZMAN DUXTANNo ratings yet
- Unbalanced and Small Sample Deep Learning For COVID X-Ray ClassificationDocument13 pagesUnbalanced and Small Sample Deep Learning For COVID X-Ray ClassificationS. SreeRamaVamsidharNo ratings yet
- Probability and Non-Probability Samples LMU Munich 2022Document22 pagesProbability and Non-Probability Samples LMU Munich 2022mehboob aliNo ratings yet
- Averaged and Weighted Average Partial Least Squares: M.H. Zhang, Q.S. Xu, D.L. MassartDocument11 pagesAveraged and Weighted Average Partial Least Squares: M.H. Zhang, Q.S. Xu, D.L. MassartAnonymous cVJKeIOLBNNo ratings yet
- This Content Downloaded From 115.27.214.77 On Thu, 01 Dec 2022 06:58:36 UTCDocument18 pagesThis Content Downloaded From 115.27.214.77 On Thu, 01 Dec 2022 06:58:36 UTCyanxiaNo ratings yet
- James Ford Et Al - Patient Classi Cation of fMRI Activation MapsDocument8 pagesJames Ford Et Al - Patient Classi Cation of fMRI Activation MapsNoScriptNo ratings yet
- Iijcs 2014 07 19 18Document7 pagesIijcs 2014 07 19 18International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Nonparametric multivariate analysis in RDocument18 pagesNonparametric multivariate analysis in RÚt NhỏNo ratings yet
- Geostatistics. Many Statistical Tools Are UsefulDocument7 pagesGeostatistics. Many Statistical Tools Are UsefulzzzaNo ratings yet
- School of Biomedical Engineering, Southern Medical University, Guangzhou 510515, ChinaDocument4 pagesSchool of Biomedical Engineering, Southern Medical University, Guangzhou 510515, ChinaTosh JainNo ratings yet
- A New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeFrom EverandA New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeNo ratings yet
- 1 s2.0 S0003267013004224 Main PDFDocument19 pages1 s2.0 S0003267013004224 Main PDFIvan TrifkovićNo ratings yet
- Audit SamplingDocument6 pagesAudit SamplingIvan TrifkovićNo ratings yet
- 1 s2.0 S0003267013004224 Main PDFDocument19 pages1 s2.0 S0003267013004224 Main PDFIvan TrifkovićNo ratings yet
- Audit SamplingDocument6 pagesAudit SamplingIvan TrifkovićNo ratings yet
- Audit SamplingDocument6 pagesAudit SamplingIvan TrifkovićNo ratings yet
- Audit SamplingDocument6 pagesAudit SamplingIvan TrifkovićNo ratings yet
- Audit SamplingDocument6 pagesAudit SamplingIvan TrifkovićNo ratings yet
- MilicaDocument1 pageMilicaIvan TrifkovićNo ratings yet
- Independence of AttributesDocument24 pagesIndependence of Attributesviswa dNo ratings yet
- Correlation Coefficient DefinitionDocument8 pagesCorrelation Coefficient DefinitionStatistics and Entertainment100% (1)
- In Vitro Blood Gas Analyzers: × 3.0 × 2.85 Inches/22.4 Ounces × 3.4 × 8.5 Inches/ 1.5 Pounds × 12 × 12 Inches/29.5 PoundsDocument8 pagesIn Vitro Blood Gas Analyzers: × 3.0 × 2.85 Inches/22.4 Ounces × 3.4 × 8.5 Inches/ 1.5 Pounds × 12 × 12 Inches/29.5 PoundsMSKNo ratings yet
- Group 5 - Concept Paper RevisedDocument19 pagesGroup 5 - Concept Paper RevisedHanz Christian PadiosNo ratings yet
- Auto Chemistry Analyzer Operation ManualDocument228 pagesAuto Chemistry Analyzer Operation ManualMichel MontemayorNo ratings yet
- Sme Thesis PDFDocument6 pagesSme Thesis PDFgcqbyfdj100% (2)
- Quantitative Technique: Subject Code: IMT-24Document7 pagesQuantitative Technique: Subject Code: IMT-24Asis LaskarNo ratings yet
- IT 102A - Lesson 5Document5 pagesIT 102A - Lesson 5John Patrick MercurioNo ratings yet
- Passenger Satisfaction Prediction: Asaaju BabatundeDocument10 pagesPassenger Satisfaction Prediction: Asaaju BabatundeTunde Asaaju100% (1)
- Lecture 1 - Quantitative SkillsDocument40 pagesLecture 1 - Quantitative SkillsMamadou Sangare100% (1)
- Cronbachs-Alpha Output With InterpretationDocument4 pagesCronbachs-Alpha Output With InterpretationRona May EsperanzateNo ratings yet
- Real SS1 Tourism First TermDocument37 pagesReal SS1 Tourism First TermElfieNo ratings yet
- ENEE621 HW1: Bayes, Neyman-Pearson and Minimax TestsDocument7 pagesENEE621 HW1: Bayes, Neyman-Pearson and Minimax TestsArif WahlaNo ratings yet
- Disaster Preparedness in Philippine Nurses: World HealthDocument8 pagesDisaster Preparedness in Philippine Nurses: World HealthBudi WidiyantoNo ratings yet
- Benford 'S LawDocument29 pagesBenford 'S LawramanathanseshaNo ratings yet
- Questions 2Document2 pagesQuestions 2gobiguptaNo ratings yet
- Assignment 2-Mat2377-2018 PDFDocument2 pagesAssignment 2-Mat2377-2018 PDFJonny diggleNo ratings yet
- The Perception of T I P Q C Selected SeDocument31 pagesThe Perception of T I P Q C Selected SeLady anne PulidoNo ratings yet
- Ch. 8. Data Analysis and ResultsDocument27 pagesCh. 8. Data Analysis and ResultsBelmin BeganovićNo ratings yet
- StudyGuide001 2015 4 B STA1502Document116 pagesStudyGuide001 2015 4 B STA1502JasonNo ratings yet
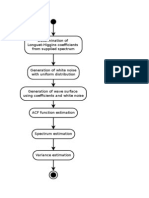
- Longuet Higgins AlgorithmDocument1 pageLonguet Higgins AlgorithmnaymyothwinNo ratings yet
- Chapter 2 Instructional Leadership David NG Foo SeongDocument35 pagesChapter 2 Instructional Leadership David NG Foo SeongWellingtonNo ratings yet
- Problem Set On Poisson ProcessDocument2 pagesProblem Set On Poisson Process21bit026No ratings yet
- Stats Intro LessonDocument6 pagesStats Intro Lessonapi-313961853No ratings yet
- MarketingDocument7 pagesMarketingDigit GoNo ratings yet
- Avm Standard 2018Document38 pagesAvm Standard 2018DiegoNo ratings yet
- Chapter 6 - SDocument4 pagesChapter 6 - SNathalie HeartNo ratings yet
- Astm E178Document18 pagesAstm E178AlbertoNo ratings yet
- Disciplines of Inquiry in Education - An OverviewDocument10 pagesDisciplines of Inquiry in Education - An OverviewDiplomado elearningNo ratings yet
- Anand USDOJ Foia Request ExpeditedDocument20 pagesAnand USDOJ Foia Request ExpeditedNeil AnandNo ratings yet