You might also like
- Problemas resueltos de Hidráulica de CanalesFrom EverandProblemas resueltos de Hidráulica de CanalesRating: 4.5 out of 5 stars4.5/5 (7)
- Métodos Matriciales para ingenieros con MATLABFrom EverandMétodos Matriciales para ingenieros con MATLABRating: 5 out of 5 stars5/5 (1)
- Actividad de Aprendizaje 3 Evidencia Momentos de VerdadDocument11 pagesActividad de Aprendizaje 3 Evidencia Momentos de VerdadDiana Marcela Góngora Rincones64% (14)
- Matriz de Análisis de Riesgo Laboral en Unaempresa AzucareraDocument11 pagesMatriz de Análisis de Riesgo Laboral en Unaempresa AzucareraWillyNo ratings yet
- Formato de Trazabilidad DESARROLLADODocument63 pagesFormato de Trazabilidad DESARROLLADODeicy ValenciaNo ratings yet
- Lunahuana, Plan Urbano 2020Document24 pagesLunahuana, Plan Urbano 2020Jean Pool Ramos SamánNo ratings yet
- Tesla MotorsDocument3 pagesTesla Motorstheoq50% (2)
- Centrales HidroeléctricasDocument14 pagesCentrales Hidroeléctricasjuanalberto123450% (4)
- Envasado ActivoDocument58 pagesEnvasado ActivonatashaNo ratings yet
- Controldigital-Libro de TextoDocument21 pagesControldigital-Libro de TextoNate River0% (1)
- EJERCICIO DE CLASE 1nDocument6 pagesEJERCICIO DE CLASE 1nLuis MartínezNo ratings yet
- EvaluacionFinal Grupo 2Document24 pagesEvaluacionFinal Grupo 2Luis German CeronNo ratings yet
- Pauta Quiz1 MCODocument26 pagesPauta Quiz1 MCOMarianita RauqueNo ratings yet
- Ejemplo Regresion Exponencial en Lenguaje RDocument2 pagesEjemplo Regresion Exponencial en Lenguaje RJose FranceschiNo ratings yet
- Distribucion de WeibullDocument10 pagesDistribucion de WeibullJoe LynchNo ratings yet
- Tarea #3 Capítulos 5, 6: OCT/2020 A-71 7 Actuaría Dr. Eduardo Rosas Luis Felipe Martinez Lopez 1625925Document8 pagesTarea #3 Capítulos 5, 6: OCT/2020 A-71 7 Actuaría Dr. Eduardo Rosas Luis Felipe Martinez Lopez 1625925Luis MartínezNo ratings yet
- SCD Lab1 - Puma - 2019aDocument42 pagesSCD Lab1 - Puma - 2019aJano Jesus AlexNo ratings yet
- Problemas Aplicados A La Ingenieria QuimicaDocument48 pagesProblemas Aplicados A La Ingenieria QuimicaKate Hdez100% (2)
- Tarea Econometr A PDFDocument7 pagesTarea Econometr A PDFAlexis Enrique Sucasaca VeraNo ratings yet
- Mru-MruvDocument8 pagesMru-MruvFatima Leiva ChiribogaNo ratings yet
- Proyecto MatemáticaDocument19 pagesProyecto MatemáticaReinaldoGruberNo ratings yet
- Lab Control 4Document17 pagesLab Control 4Saul Larico AlmonteNo ratings yet
- Reporte - Unidad1 - MetodosNumericos - Equipo 2Document16 pagesReporte - Unidad1 - MetodosNumericos - Equipo 2Manuel AlejandroNo ratings yet
- Act5Document12 pagesAct5mileth.irazema14No ratings yet
- Identificar modelo y estabilidadDocument13 pagesIdentificar modelo y estabilidadmarco riconNo ratings yet
- Estadistica Aplicada . - Tarea 2Document10 pagesEstadistica Aplicada . - Tarea 2Marco OviedoNo ratings yet
- CODIES2022 - Cap6 - Regulador PIDDocument12 pagesCODIES2022 - Cap6 - Regulador PIDJose BiaforeNo ratings yet
- 1 - Paso - Consolidado (1) Control DigitalDocument13 pages1 - Paso - Consolidado (1) Control DigitalManuel GarciaNo ratings yet
- Determinación nivel calidad procesos sigma vs dpmDocument36 pagesDeterminación nivel calidad procesos sigma vs dpmJareck DeejNo ratings yet
- TDC Práctica 8 - Sintonización Ziegler-NicholsDocument6 pagesTDC Práctica 8 - Sintonización Ziegler-NicholsSebastián TorresNo ratings yet
- Laboratorio 1 de SeñalesDocument9 pagesLaboratorio 1 de SeñalesGustavo LapaNo ratings yet
- Lección1 CalculadoraDocument17 pagesLección1 CalculadoraAlejandro Cisterna GarciaNo ratings yet
- Bitacora 2 Final PDFDocument10 pagesBitacora 2 Final PDFGina SanchezNo ratings yet
- RLS y RLMDocument7 pagesRLS y RLMDa FrankoNo ratings yet
- Análisis de regresión lineal de datos experimentalesDocument15 pagesAnálisis de regresión lineal de datos experimentalesChristiaan GodoyNo ratings yet
- RTARC. - Determinacion de K y N (Problema 13)Document8 pagesRTARC. - Determinacion de K y N (Problema 13)Carlos LoachaminNo ratings yet
- funciones matemáticas matlab límitesDocument56 pagesfunciones matemáticas matlab límitesJuan camilo Ponce SegoviaNo ratings yet
- Método de RungeKutta2do OrdenDocument4 pagesMétodo de RungeKutta2do OrdenFranck PatruNo ratings yet
- Sistemas DiscretosDocument32 pagesSistemas DiscretosVanessa DelgadoNo ratings yet
- Tablas Controlador Pid Lazo AbiertoDocument9 pagesTablas Controlador Pid Lazo AbiertoLuis Daniel Rodriguez VeraNo ratings yet
- Interpolación numérica con métodos de Newton y LagrangeDocument12 pagesInterpolación numérica con métodos de Newton y LagrangePeter PittmanNo ratings yet
- MO Tarea2 Merged PDFDocument17 pagesMO Tarea2 Merged PDFGerman Galdamez OvandoNo ratings yet
- Eval Corta Alex Nova 2175587 CorregidaDocument10 pagesEval Corta Alex Nova 2175587 CorregidaAlex David Nova ArdilaNo ratings yet
- Práctica de Regresión Lineal Entregar 1Document4 pagesPráctica de Regresión Lineal Entregar 1Pablo Lozano FernandezNo ratings yet
- Informe Control 2Document22 pagesInforme Control 2Sammy PerdomoNo ratings yet
- Ordinario MnoDocument9 pagesOrdinario Mnopuas911No ratings yet
- Ayudantia - 2 - 2021 Time SeriesDocument4 pagesAyudantia - 2 - 2021 Time SeriesAndrés EspinozaNo ratings yet
- Interpretación de Los Coeficientes PDFDocument5 pagesInterpretación de Los Coeficientes PDFjuniorNo ratings yet
- 05 Fase1Document10 pages05 Fase1Edwin Javier Diaz PerezNo ratings yet
- Soluciones Unidad 3 OpcionalesDocument15 pagesSoluciones Unidad 3 OpcionalesJaume BcNo ratings yet
- Practica Control Optimo Con MATLABDocument15 pagesPractica Control Optimo Con MATLABDavid ChoquehuancaNo ratings yet
- Capitulo V Ing de Mantenimiento Gestion Economica de MantenimientoDocument50 pagesCapitulo V Ing de Mantenimiento Gestion Economica de MantenimientoErnesto Huillca QuispeNo ratings yet
- Fase 5 - Trabajo PrácticoDocument18 pagesFase 5 - Trabajo PrácticoJairo GuevaraNo ratings yet
- TALLER Nº3 Mateaplica2Document11 pagesTALLER Nº3 Mateaplica2ronni bermudezNo ratings yet
- Tarea 2.1 CaroDocument14 pagesTarea 2.1 CaroDaniel PancheNo ratings yet
- Practicas Control Resumen CompletoDocument36 pagesPracticas Control Resumen CompletoAlejandro Sánchez GarcésNo ratings yet
- Practica de Econometria02Document25 pagesPractica de Econometria02Natan Mendoza ChiroqueNo ratings yet
- Analisis de Sistemas Lineales Empleando Matlab V - 0.1Document10 pagesAnalisis de Sistemas Lineales Empleando Matlab V - 0.1Yuki RitoNo ratings yet
- Teoria Economia de MecanizadoDocument9 pagesTeoria Economia de MecanizadoEltrobadorNo ratings yet
- Clase 01 PythonDocument3 pagesClase 01 PythonwilfredoNo ratings yet
- Regresion Lineal Simple Seleccion de Actividades ResueltasDocument20 pagesRegresion Lineal Simple Seleccion de Actividades ResueltasEduardo Sánchez HernándezNo ratings yet
- Analisis Numerico Examen 1 Espol Dic 2008Document5 pagesAnalisis Numerico Examen 1 Espol Dic 2008Eduardo SerranoNo ratings yet
- La Ecuación de Van Der WaalsDocument12 pagesLa Ecuación de Van Der WaalsAmérico RumínNo ratings yet
- Linfoma HodgkinDocument5 pagesLinfoma HodgkintheoqNo ratings yet
- Clínica Por EnfermedadesDocument1 pageClínica Por EnfermedadestheoqNo ratings yet
- Prácticas de RDocument16 pagesPrácticas de RtheoqNo ratings yet
- Interprete de ComandosDocument8 pagesInterprete de ComandostheoqNo ratings yet
- Linfoma Hodgkin TTODocument1 pageLinfoma Hodgkin TTOtheoqNo ratings yet
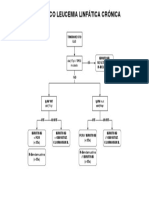
- LLC TtoDocument1 pageLLC TtotheoqNo ratings yet
- Afectación ArticularDocument1 pageAfectación ArticulartheoqNo ratings yet
- Fusión Nuclear Por Confinamiento InercialDocument3 pagesFusión Nuclear Por Confinamiento InercialtheoqNo ratings yet
- PÁNCREASDocument3 pagesPÁNCREAStheoqNo ratings yet
- Fundamentos de Automática con MATLABDocument52 pagesFundamentos de Automática con MATLABtheoqNo ratings yet
- Notas Corte 2017-2018 Junio MADRIDDocument10 pagesNotas Corte 2017-2018 Junio MADRIDtheoqNo ratings yet
- Gamma y Beta de EulerDocument13 pagesGamma y Beta de Eulertheoq100% (1)
- CNG RecorridoDocument16 pagesCNG RecorridotheoqNo ratings yet
- AC Junio12 P2Document1 pageAC Junio12 P2theoqNo ratings yet
- Beta/Euler Gamma Integrals ETSIIDocument1 pageBeta/Euler Gamma Integrals ETSIItheoqNo ratings yet
- WWII - Spanish Summary - ESODocument3 pagesWWII - Spanish Summary - ESOtheoqNo ratings yet
- Beta/Euler Gamma Integrals ETSIIDocument1 pageBeta/Euler Gamma Integrals ETSIItheoqNo ratings yet
- Isabel 2 - Apuntes ESODocument4 pagesIsabel 2 - Apuntes ESOtheoqNo ratings yet
- Resumen FÍSICA 1 PEC 1 GITIDocument2 pagesResumen FÍSICA 1 PEC 1 GITItheoqNo ratings yet
- Pan or Ma ADocument1 pagePan or Ma AtheoqNo ratings yet
- ПРЕДЛОЖНЫЙ ПАДЕЖDocument1 pageПРЕДЛОЖНЫЙ ПАДЕЖtheoqNo ratings yet
- About Keyboard ShortcutsDocument4 pagesAbout Keyboard ShortcutstheoqNo ratings yet
- Arduino Severino Componentes ListDocument6 pagesArduino Severino Componentes ListtheoqNo ratings yet
- Inventario Puerto Montt SPWDocument20 pagesInventario Puerto Montt SPWMaría Laura Zapata RomeroNo ratings yet
- Vicens Vives-La Sociedad BarrocaDocument4 pagesVicens Vives-La Sociedad BarrocaAlan RickertNo ratings yet
- Leyes de Kirchhoff de circuitos eléctricos (38Document17 pagesLeyes de Kirchhoff de circuitos eléctricos (38Nico AvalosNo ratings yet
- Especificaciones Tecnicas CantuDocument75 pagesEspecificaciones Tecnicas CantuCarlos A. Martínez BenaventeNo ratings yet
- GUÍA N°02 - Movimiento Armonico SimpleDocument11 pagesGUÍA N°02 - Movimiento Armonico SimpleYanira Gutierrez BalderaNo ratings yet
- Postweld Heat Treatment (PWHT)Document2 pagesPostweld Heat Treatment (PWHT)Freddy Lagua PerezNo ratings yet
- Desbridamiento de quemadurasDocument4 pagesDesbridamiento de quemadurasEva Gomez Gutierrez100% (1)
- Johanna Mancilla Quintana Cuarentena Informe PDFDocument11 pagesJohanna Mancilla Quintana Cuarentena Informe PDFJohanna MancillaNo ratings yet
- Taller Administración DeportivaDocument1 pageTaller Administración Deportivajavier javier100% (2)
- WEG Almacenaje de Maquinas Electricas Girantes de Mediano Porte Articulo Tecnico Espanol PDFDocument0 pagesWEG Almacenaje de Maquinas Electricas Girantes de Mediano Porte Articulo Tecnico Espanol PDFgastoksNo ratings yet
- SistemasJurídicosIndiaFilipinasSudáfricaDocument5 pagesSistemasJurídicosIndiaFilipinasSudáfricaGarritas Moda Para PerritosNo ratings yet
- Infome de Gestión 2019-2022Document36 pagesInfome de Gestión 2019-2022Comunicaciones Ciencias Económicas Universidad de AntioquiaNo ratings yet
- Derecho Procesal ApunteDocument12 pagesDerecho Procesal ApunteRomina Silva TorresNo ratings yet
- Cotizacion Navi-Toyota Agua y DesgaueDocument3 pagesCotizacion Navi-Toyota Agua y DesgaueAngel LopezNo ratings yet
- Estudios de Suelos Calle 60 N 50A 64 VEGACHI Fabian Perez 2022Document35 pagesEstudios de Suelos Calle 60 N 50A 64 VEGACHI Fabian Perez 2022Fernando GomezNo ratings yet
- Novedades Prescom - 2011Document8 pagesNovedades Prescom - 2011Danny Quispe TapiaNo ratings yet
- Clasificación y Características de Los Tipos de TecnologiaDocument3 pagesClasificación y Características de Los Tipos de TecnologiaRouss LopezNo ratings yet
- Evaluación Formaciones Mediante RegistrosDocument5 pagesEvaluación Formaciones Mediante RegistrosFroilan CollNo ratings yet
- Arreglo 4K X 8 Con 512 X 4Document8 pagesArreglo 4K X 8 Con 512 X 4arto99styleNo ratings yet
- DEDICATORIADocument14 pagesDEDICATORIAgabriel soplopucoNo ratings yet
- Informe de Pago y Cobro Sin ConclusionesDocument7 pagesInforme de Pago y Cobro Sin ConclusionesMaria Lizeth Burga ÑiqueNo ratings yet
- SimuladoresDocument4 pagesSimuladoresYahana Villatoro HernandezNo ratings yet
- PlanillaDocument2 pagesPlanillaMiguel Ángel Hernández PérezNo ratings yet
- Constitución SAC Yellow GroupDocument16 pagesConstitución SAC Yellow GroupGloria RodríguezNo ratings yet