You might also like
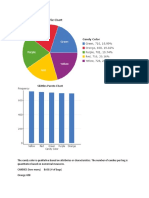
- Skittles Project With ReflectionDocument7 pagesSkittles Project With Reflectionapi-234712126100% (1)
- Math 1040 Term Project - Skittles 2Document6 pagesMath 1040 Term Project - Skittles 2api-313998583No ratings yet
- Teste de HipóteseDocument6 pagesTeste de HipóteseAntonio MonteiroNo ratings yet
- Skittles Term Project ReflectionDocument12 pagesSkittles Term Project Reflectionapi-272673268100% (1)
- Stats Project FinalDocument10 pagesStats Project Finalapi-316977780No ratings yet
- Stats 250 W12 Exam 1 SolutionsDocument7 pagesStats 250 W12 Exam 1 SolutionsScottNo ratings yet
- Complete NotesDocument153 pagesComplete NotesSungsoo KimNo ratings yet
- EstimationDocument27 pagesEstimationLaila Syaheera Md KhalilNo ratings yet
- Doane - Stats - Chap 007 - Test AnswersDocument83 pagesDoane - Stats - Chap 007 - Test AnswersBG Monty 1100% (2)
- 4818 Exam2aDocument5 pages4818 Exam2aMaliha JahanNo ratings yet
- DOANE - Stats Answer Key Chap 008Document73 pagesDOANE - Stats Answer Key Chap 008BG Monty 1100% (1)
- WINSEM2015-16 CP1615 18-MAR-2016 RM01 Z-Test For Means and ProprtionsDocument7 pagesWINSEM2015-16 CP1615 18-MAR-2016 RM01 Z-Test For Means and Proprtionsgowtham0% (2)
- Skittles Project Part 2Document4 pagesSkittles Project Part 2api-533983196No ratings yet
- Homework M2 SolutionDocument9 pagesHomework M2 Solutionbonface mukuvaNo ratings yet
- I P S F E Sampling Distributions: Ntroduction To Robability AND Tatistics Ourteenth DitionDocument37 pagesI P S F E Sampling Distributions: Ntroduction To Robability AND Tatistics Ourteenth DitionRicky Justin NgoNo ratings yet
- Workshop 06 - S1 - 2020 - Solutions For Business StatisticsDocument6 pagesWorkshop 06 - S1 - 2020 - Solutions For Business StatisticsKrithik MehtaNo ratings yet
- Descriptive StatisticsDocument83 pagesDescriptive StatisticsVishvajit KumbharNo ratings yet
- Math 1040 - Part IV Skittles ProjectDocument7 pagesMath 1040 - Part IV Skittles Projectapi-441885867No ratings yet
- Math Studies IaDocument6 pagesMath Studies Iaapi-285168683No ratings yet
- Sample Size Recalculation in Internal Pilot Study Designs - A Review PDFDocument19 pagesSample Size Recalculation in Internal Pilot Study Designs - A Review PDFnelson huaytaNo ratings yet
- HW Chapters 8 Confidence IntervalsDocument4 pagesHW Chapters 8 Confidence IntervalsKawtar AallamNo ratings yet
- Ch07 StatisticsDocument29 pagesCh07 StatisticsSubhajit DasNo ratings yet
- Skittles Project Part 3 TemplateDocument2 pagesSkittles Project Part 3 Templateapi-325272106No ratings yet
- Questions & Answers Chapter - 7 Set 1Document6 pagesQuestions & Answers Chapter - 7 Set 1FaridOrahaNo ratings yet
- Tests of Significance and Measures of Association ExplainedDocument21 pagesTests of Significance and Measures of Association Explainedanandan777supmNo ratings yet
- Introduction To Business MathematicsDocument44 pagesIntroduction To Business MathematicsAbdullah ZakariyyaNo ratings yet
- Mrudula Sonewane ML Project BusinessReport Oct B 22Document31 pagesMrudula Sonewane ML Project BusinessReport Oct B 22Anand KhobragadeNo ratings yet
- Lec Set 1 Data AnalysisDocument55 pagesLec Set 1 Data AnalysisSmarika KulshresthaNo ratings yet
- Lect 18Document18 pagesLect 18Gaurav AgarwalNo ratings yet
- 10 Cluster AnalysisDocument13 pages10 Cluster Analysisdéborah_rosalesNo ratings yet
- Measures of Central TendencyDocument39 pagesMeasures of Central TendencyShivam SrivastavaNo ratings yet
- Complete Business Statistics: Multivariate AnalysisDocument25 pagesComplete Business Statistics: Multivariate Analysismallick5051rajatNo ratings yet
- Regression Analysis ResultsDocument7 pagesRegression Analysis ResultsMübashir KhanNo ratings yet
- Part I: Modeling Exponential Growth Skittles Activity: Don'T Eat The Skittles Until You Are Done With The ProjectDocument8 pagesPart I: Modeling Exponential Growth Skittles Activity: Don'T Eat The Skittles Until You Are Done With The ProjectMonica RiveraNo ratings yet
- Chicago Booth BUS 41100 Practice Final Exam Fall 2020 SolutionsDocument7 pagesChicago Booth BUS 41100 Practice Final Exam Fall 2020 SolutionsJohnNo ratings yet
- Uncertainties and Significant FiguresDocument4 pagesUncertainties and Significant FiguresgraceNo ratings yet
- 1112sem1 ST5203Document14 pages1112sem1 ST5203jiashengroxNo ratings yet
- Stats 250 W15 Exam 2 SolutionsDocument8 pagesStats 250 W15 Exam 2 SolutionsHamza AliNo ratings yet
- 5.1 Simulation Determinatic BehaviourDocument7 pages5.1 Simulation Determinatic Behaviourriadimazz_910414786No ratings yet
- Lesson 12 T Test Dependent SamplesDocument26 pagesLesson 12 T Test Dependent SamplesNicole Daphnie LisNo ratings yet
- Stat2507 FinalexamDocument12 pagesStat2507 Finalexamyana22No ratings yet
- Ch4 Testbank Handout PDFDocument5 pagesCh4 Testbank Handout PDFHassan HussainNo ratings yet
- Chapter13 SlidesDocument24 pagesChapter13 SlidesParth Rajesh ShethNo ratings yet
- BUMK 742 - Project 1 PDFDocument11 pagesBUMK 742 - Project 1 PDFYiyang WangNo ratings yet
- Quantitative Techniques in FinanceDocument31 pagesQuantitative Techniques in FinanceAshraj_16No ratings yet
- CH 01 TestDocument22 pagesCH 01 TestNeeti GurunathNo ratings yet
- The Drongo's Guide To UncertaintyDocument8 pagesThe Drongo's Guide To UncertaintyMac YusufNo ratings yet
- STA6166 HW1 Ramin Shamshiri SolutionDocument9 pagesSTA6166 HW1 Ramin Shamshiri SolutionRedmond R. ShamshiriNo ratings yet
- Free Fall Acceleration and Error AnalysisDocument3 pagesFree Fall Acceleration and Error Analysisnrl syafiqa100% (1)
- Stat HandoutDocument7 pagesStat HandoutJenrick DimayugaNo ratings yet
- Qam Ii - Ps 3 AnsDocument8 pagesQam Ii - Ps 3 AnsSayantan NandyNo ratings yet
- Complete Business Statistics: The Comparison of Two PopulationsDocument66 pagesComplete Business Statistics: The Comparison of Two Populationsmallick5051rajatNo ratings yet
- Chapter 6 Prob Stat (Random Variables)Document49 pagesChapter 6 Prob Stat (Random Variables)necieNo ratings yet
- Topic11 Measurement09Document7 pagesTopic11 Measurement09Imad AghilaNo ratings yet
- Solar Radiation Prediction: Dr. Himani BansalDocument43 pagesSolar Radiation Prediction: Dr. Himani BansalHimanshu KesarwaniNo ratings yet
- Burford Final Fall2017Document11 pagesBurford Final Fall2017api-430812455No ratings yet
- Assignment 2 PDFDocument3 pagesAssignment 2 PDFAnonymous CoKqJJwWNo ratings yet
- Stats Semester ProjectDocument11 pagesStats Semester Projectapi-276989071No ratings yet
- Skittles Project 2-6Document8 pagesSkittles Project 2-6api-302525501No ratings yet
- Statistics Project 17Document13 pagesStatistics Project 17api-271978152No ratings yet
- Make To Order Strategies - Strategy 20 - SAP BlogsDocument16 pagesMake To Order Strategies - Strategy 20 - SAP BlogsbhaskarSNo ratings yet
- XL VU Video ProbeDocument4 pagesXL VU Video ProbeSahrijal PurbaNo ratings yet
- Nandeck ManualDocument122 pagesNandeck ManualDragan ZivoticNo ratings yet
- Sap Travel ManagementDocument7 pagesSap Travel Managementejas.cbit100% (1)
- Solving The Large-Scale TSP Problem in 1h: Santa Claus Challenge 2020Document20 pagesSolving The Large-Scale TSP Problem in 1h: Santa Claus Challenge 2020Isabella IsaNo ratings yet
- Accessing SQLite Databases in PHP Using PDODocument3 pagesAccessing SQLite Databases in PHP Using PDOPedro Boanerges Paz RomeroNo ratings yet
- From Mental Maps To Geoparticipation: Jir ̌Í PánekDocument8 pagesFrom Mental Maps To Geoparticipation: Jir ̌Í PánekWilliam BrandtNo ratings yet
- Alg Linear Axminusbeqc All PDFDocument20 pagesAlg Linear Axminusbeqc All PDFNurulNo ratings yet
- OpenVov BE200/BE400 Series BRI Card DatasheetDocument1 pageOpenVov BE200/BE400 Series BRI Card Datasheetmaple4VOIPNo ratings yet
- Extending The Power BI Template For Project For The WebDocument7 pagesExtending The Power BI Template For Project For The WebMahmoud Karam100% (1)
- System Flow Diagram and Level O-OE - SDocument3 pagesSystem Flow Diagram and Level O-OE - Ssunil bhandariNo ratings yet
- Online Book Store Database Design and ScriptsDocument14 pagesOnline Book Store Database Design and ScriptsTushar ShelakeNo ratings yet
- PCM 1718Document14 pagesPCM 1718isaiasvaNo ratings yet
- Buzon. en Cuarentena Microsoft - Exchange.data - StorageDocument4 pagesBuzon. en Cuarentena Microsoft - Exchange.data - StorageLuis SotoNo ratings yet
- Pipeline and VectorDocument29 pagesPipeline and VectorGâgäñ LøhîăNo ratings yet
- Color TV: Service ManualDocument31 pagesColor TV: Service ManualiskeledzNo ratings yet
- Faculty Supervisor Evaluation Form For Project Semester: Rajat Kumar MechanicalDocument3 pagesFaculty Supervisor Evaluation Form For Project Semester: Rajat Kumar MechanicalSajal KhuranaNo ratings yet
- Unified Modeling Language (UML) : An OverviewDocument37 pagesUnified Modeling Language (UML) : An OverviewRaddad Al KingNo ratings yet
- Chris Stuart: Speaker Diaphragm, Speaker, and Method For Manufacturing Speaker DiaphragmDocument14 pagesChris Stuart: Speaker Diaphragm, Speaker, and Method For Manufacturing Speaker DiaphragmJoyce NucumNo ratings yet
- UMRN authorization formDocument1 pageUMRN authorization formPraneeth SrivanthNo ratings yet
- Feederless-SFP-DC Cables-Flexi Multiradio Base Station Installation Site Requirements PDFDocument15 pagesFeederless-SFP-DC Cables-Flexi Multiradio Base Station Installation Site Requirements PDFFlorin StanNo ratings yet
- Orphan Process: Write A Program To Create A Thread To Find The Factorial of A Natural Number N'Document40 pagesOrphan Process: Write A Program To Create A Thread To Find The Factorial of A Natural Number N'srinivasa reddyNo ratings yet
- Scada Hack SandhuDocument6 pagesScada Hack SandhuSatinder Singh SandhuNo ratings yet
- SQL Server 2008 Replication Technical Case StudyDocument44 pagesSQL Server 2008 Replication Technical Case StudyVidya SagarNo ratings yet
- Purvanchal Vidyut Vitaram Nigam LTDDocument1 pagePurvanchal Vidyut Vitaram Nigam LTDVIKAS MISHRANo ratings yet
- Sartorius Combics 3: Operating InstructionsDocument94 pagesSartorius Combics 3: Operating InstructionsSadeq NeiroukhNo ratings yet
- Meditaciones Diarias THOMAS PRINTZDocument100 pagesMeditaciones Diarias THOMAS PRINTZCristian Andres Araya CisternasNo ratings yet
- ReviewerDocument7 pagesReviewerDiana Marie Vargas CariñoNo ratings yet
- 1 Page PDF .PDF - SearchDocument6 pages1 Page PDF .PDF - Search001srvnNo ratings yet
- Control SystemDocument2 pagesControl Systemguru.rjpmNo ratings yet