You might also like
- Supporting Multi Data Stores Applications in Cloud EnvironmentsDocument6 pagesSupporting Multi Data Stores Applications in Cloud EnvironmentsVigneshInfotechNo ratings yet
- Methodology For Solving Data Portability in Cloud Information Technology EssayDocument4 pagesMethodology For Solving Data Portability in Cloud Information Technology EssayKarthik KrishnamurthiNo ratings yet
- Comparing Multiple Cloud Frameworks on FutureGridDocument8 pagesComparing Multiple Cloud Frameworks on FutureGridThiago SenaNo ratings yet
- MapReduce in Hadoop: What is MapReduce? Scalable Processing of Big DataDocument11 pagesMapReduce in Hadoop: What is MapReduce? Scalable Processing of Big DataASHISH CHAUDHARYNo ratings yet
- Senger Et Al-2016-Concurrency and Computation Practice and ExperienceDocument4 pagesSenger Et Al-2016-Concurrency and Computation Practice and ExperienceMahalingam RamaswamyNo ratings yet
- Analysis of Open Source Computing Techniques & Comparison On Cloud-Based ERPDocument7 pagesAnalysis of Open Source Computing Techniques & Comparison On Cloud-Based ERPInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- S4: Distributed Stream Computing PlatformDocument8 pagesS4: Distributed Stream Computing PlatformOtávio CarvalhoNo ratings yet
- A Federated Multi-Cloud Paas InfrastructureDocument8 pagesA Federated Multi-Cloud Paas InfrastructureWarren SmithNo ratings yet
- Semantic Modelling in Cloud ComputingDocument4 pagesSemantic Modelling in Cloud ComputingInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Md. Jakir Hossain - CC - Assign-1Document4 pagesMd. Jakir Hossain - CC - Assign-1MD Monowar Ul IslamNo ratings yet
- Minor Project ReportDocument15 pagesMinor Project ReportLakshaya TeotiaNo ratings yet
- Towards Heterogeneous Multimedia Information Systems: The Garlic ApproachDocument8 pagesTowards Heterogeneous Multimedia Information Systems: The Garlic ApproachbetsinghNo ratings yet
- Benchmarking Criteria For A Cloud Data WarehouseDocument11 pagesBenchmarking Criteria For A Cloud Data Warehousexxcabdi123No ratings yet
- Requirements to Transform IT to a ServiceDocument4 pagesRequirements to Transform IT to a ServiceMD Monowar Ul IslamNo ratings yet
- Optimizing Information Leakage in Multicloud Storage ServicesDocument27 pagesOptimizing Information Leakage in Multicloud Storage ServicesKiran Maramulla67% (3)
- Term Paper 11613442Document4 pagesTerm Paper 11613442Sowmith KolaNo ratings yet
- Scalable SQL: How Do Large-Scale Sites and Applications Remain SQL-based?Document8 pagesScalable SQL: How Do Large-Scale Sites and Applications Remain SQL-based?Mue ChNo ratings yet
- NoSQL Databases: A Step to Database Scalability in Web EnvironmentDocument17 pagesNoSQL Databases: A Step to Database Scalability in Web EnvironmentDiana RoxanaNo ratings yet
- Cloud Scalability ConsiderationsDocument11 pagesCloud Scalability ConsiderationsijcsesNo ratings yet
- The Architectural Design of Globe: A Wide-Area Distributed SystemDocument23 pagesThe Architectural Design of Globe: A Wide-Area Distributed SystemMonish ChanchlaniNo ratings yet
- Term Paper 11613442Document4 pagesTerm Paper 11613442123 456No ratings yet
- Cloud Computing: Issues and ChallengesDocument7 pagesCloud Computing: Issues and ChallengesadamNo ratings yet
- Study of Cordova Data Storage Strategies and PerformanceDocument10 pagesStudy of Cordova Data Storage Strategies and PerformanceLone FoxedNo ratings yet
- Presto SQL On EverythingDocument12 pagesPresto SQL On EverythingMartin De LucaNo ratings yet
- Research Paper On Client ServerDocument4 pagesResearch Paper On Client Serveref71d9gw100% (1)
- Management of Data Intensive Application Workflow in Cloud ComputingDocument4 pagesManagement of Data Intensive Application Workflow in Cloud ComputingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Revolution of Storms From Vendor Lock-In To The Data StorageDocument6 pagesRevolution of Storms From Vendor Lock-In To The Data StorageijcertNo ratings yet
- Open Source Cloud Computing Tools - A Case Study With A Weather ApplicationDocument7 pagesOpen Source Cloud Computing Tools - A Case Study With A Weather Applicationgjkumar_mcaNo ratings yet
- Sharna Cs DoneDocument15 pagesSharna Cs Donebalaji xeroxNo ratings yet
- Roy Fielding Rest ThesisDocument6 pagesRoy Fielding Rest Thesisjmvnqiikd100% (2)
- Report 4: Model-Driven Engineering On and For The Cloud: NtroductionDocument4 pagesReport 4: Model-Driven Engineering On and For The Cloud: Ntroductionhh HNo ratings yet
- Comparative Study: Performance of MVC Frameworks On RDBMSDocument9 pagesComparative Study: Performance of MVC Frameworks On RDBMSMdHafizurRahmanNo ratings yet
- Theodolite: Scalability Benchmarking of Distributed Stream Processing Engines in Microservice ArchitecturesDocument28 pagesTheodolite: Scalability Benchmarking of Distributed Stream Processing Engines in Microservice Architectureszaffa AfnanNo ratings yet
- Enhancing Scalability in Big Data and Cloud ComputingDocument7 pagesEnhancing Scalability in Big Data and Cloud Computingprayas jhariyaNo ratings yet
- DevOps Patterns To Scale Web Applications Using Cloud ServicesDocument10 pagesDevOps Patterns To Scale Web Applications Using Cloud ServicesDaniel CukierNo ratings yet
- Ijettcs 2013 08 24 111Document8 pagesIjettcs 2013 08 24 111International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- 07 Automated Data MigrationDocument9 pages07 Automated Data MigrationpabloNo ratings yet
- Database As A Service (Dbaas) : Wolfgang Lehner, Kai-Uwe SattlerDocument2 pagesDatabase As A Service (Dbaas) : Wolfgang Lehner, Kai-Uwe SattlerSreenidhi M SriramNo ratings yet
- RefCardz - Getting Started With MicroservicesDocument6 pagesRefCardz - Getting Started With MicroservicesajulienNo ratings yet
- Ensuring Cloud Data Storage Security with Distributed Verification and Error LocalizationDocument5 pagesEnsuring Cloud Data Storage Security with Distributed Verification and Error Localizationdevangana1991No ratings yet
- A Survey of IoT Cloud ProvidersDocument6 pagesA Survey of IoT Cloud ProvidersAmir AzrenNo ratings yet
- Data Modeling Foundations for Data ScienceDocument50 pagesData Modeling Foundations for Data ScienceHENDRA GUNAWANNo ratings yet
- Distributed Query Processing +Document19 pagesDistributed Query Processing +Prashant DeepNo ratings yet
- Big Data Dan Cloud ComputingDocument19 pagesBig Data Dan Cloud ComputingKarenNo ratings yet
- The Next Database Revolution: Jim Gray Microsoft 455 Market St. #1650 San Francisco, CA, 94105 USADocument4 pagesThe Next Database Revolution: Jim Gray Microsoft 455 Market St. #1650 San Francisco, CA, 94105 USAnguyendinh126No ratings yet
- Dynamically Integrating Knowledge in Applications. An Online Scoring Engine ArchitectureDocument6 pagesDynamically Integrating Knowledge in Applications. An Online Scoring Engine ArchitectureefemeritateNo ratings yet
- Verification of Data Integrity in Co-Operative Multicloud StorageDocument9 pagesVerification of Data Integrity in Co-Operative Multicloud Storagedreamka12No ratings yet
- Cloud Native AppDocument176 pagesCloud Native Appthe4powerNo ratings yet
- Microservices PDFDocument6 pagesMicroservices PDFMahendar SNo ratings yet
- Futureinternet 04 00322Document25 pagesFutureinternet 04 00322Arijit SarkarNo ratings yet
- Critical Analysis of Ecm Applications in The Clouds: A Case StudyDocument12 pagesCritical Analysis of Ecm Applications in The Clouds: A Case StudyAnonymous Gl4IRRjzNNo ratings yet
- Open Source Cloud Computing Tools: A Case Study With A Weather ApplicationDocument7 pagesOpen Source Cloud Computing Tools: A Case Study With A Weather Applicationvinaykumargupta1992No ratings yet
- Chapter OneDocument25 pagesChapter OneIbro ZaneNo ratings yet
- Data Management Iot Bigdata Cloud ScadaDocument11 pagesData Management Iot Bigdata Cloud ScadatrivediurvishNo ratings yet
- Db4o Reference JavaDocument252 pagesDb4o Reference JavaEdson BtNo ratings yet
- Cloud Computing Lab Manual 1Document25 pagesCloud Computing Lab Manual 1OMSAINATH MPONLINE100% (1)
- 1 s2.0 S0167739X11001440 MainDocument14 pages1 s2.0 S0167739X11001440 MainSaravanan ThangasamyNo ratings yet
- Microsoft Azure Storage Essentials - Sample ChapterDocument18 pagesMicrosoft Azure Storage Essentials - Sample ChapterPackt PublishingNo ratings yet
- The Ultimate Guide to Unlocking the Full Potential of Cloud Services: Tips, Recommendations, and Strategies for SuccessFrom EverandThe Ultimate Guide to Unlocking the Full Potential of Cloud Services: Tips, Recommendations, and Strategies for SuccessNo ratings yet
- Preparation of Papers in Two-Column Format For Publications of IEIDocument3 pagesPreparation of Papers in Two-Column Format For Publications of IEIVigneshInfotechNo ratings yet
- Saitej Resume DoneDocument2 pagesSaitej Resume DoneVigneshInfotechNo ratings yet
- de-220121-180442-M.Tech - M.Pharm Supply Project Thesis Uploading Notification Jan-2022Document3 pagesde-220121-180442-M.Tech - M.Pharm Supply Project Thesis Uploading Notification Jan-2022VigneshInfotechNo ratings yet
- Employee school visit report with school detailsDocument4 pagesEmployee school visit report with school detailsVigneshInfotechNo ratings yet
- 1 5177093672394555706Document2 pages1 5177093672394555706VigneshInfotechNo ratings yet
- Numbers: 5 and 6 Digits: AnswersDocument37 pagesNumbers: 5 and 6 Digits: AnswersVigneshInfotechNo ratings yet
- Data Leakage DetectionDocument26 pagesData Leakage DetectionVigneshInfotechNo ratings yet
- Your Family and NeighbourhoodDocument30 pagesYour Family and NeighbourhoodVigneshInfotechNo ratings yet
- CV SaberDocument3 pagesCV SaberVigneshInfotechNo ratings yet
- Low Power - Area Efficient Multiplexer Restructuring For VLSI ImplementationDocument8 pagesLow Power - Area Efficient Multiplexer Restructuring For VLSI ImplementationVigneshInfotechNo ratings yet
- 2 MasDocument29 pages2 MasVigneshInfotechNo ratings yet
- Ambedkar Jagarla: Email: Ambedkarj010Document2 pagesAmbedkar Jagarla: Email: Ambedkarj010VigneshInfotechNo ratings yet
- Matlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'Document1 pageMatlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'VigneshInfotechNo ratings yet
- An Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorDocument39 pagesAn Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorVigneshInfotechNo ratings yet
- 24-Mar-2019, CC, BZA - KZJDocument2 pages24-Mar-2019, CC, BZA - KZJVigneshInfotechNo ratings yet
- Performance analysis of BPSK and DPSK under Nakagami fadingDocument5 pagesPerformance analysis of BPSK and DPSK under Nakagami fadingVigneshInfotechNo ratings yet
- 1 EngDocument32 pages1 EngVigneshInfotechNo ratings yet
- STUDENT Name:: Mundada Vinay Kumar EmailDocument2 pagesSTUDENT Name:: Mundada Vinay Kumar EmailVigneshInfotechNo ratings yet
- 2 Evs PDFDocument39 pages2 Evs PDFVigneshInfotechNo ratings yet
- Project Documentation Guidelines - ECE - JITS2013Document4 pagesProject Documentation Guidelines - ECE - JITS2013VigneshInfotechNo ratings yet
- FCDocument1 pageFCVigneshInfotechNo ratings yet
- FCDocument5 pagesFCVigneshInfotechNo ratings yet
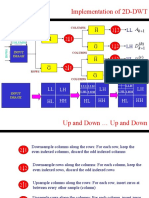
- Implementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHDocument4 pagesImplementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHVigneshInfotechNo ratings yet
- Final Wifi 2Document87 pagesFinal Wifi 2VigneshInfotechNo ratings yet
- Discrete Wavelet TransformDocument10 pagesDiscrete Wavelet TransformVigneshInfotechNo ratings yet
- A New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmDocument8 pagesA New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmVigneshInfotechNo ratings yet
- Image Denoising Using Wavelet Shrinkage TechniquesDocument60 pagesImage Denoising Using Wavelet Shrinkage TechniquesVigneshInfotechNo ratings yet
- Error Detection and Data Recovery for Motion Estimation TestingDocument3 pagesError Detection and Data Recovery for Motion Estimation TestingVigneshInfotechNo ratings yet
- Design and Implementation of Area-Optimized AES Based On FPGADocument4 pagesDesign and Implementation of Area-Optimized AES Based On FPGAVigneshInfotechNo ratings yet
- 5and 6Document15 pages5and 6VigneshInfotechNo ratings yet
- Case Study Based On: Cloud Deployment and Service Delivery ModelsDocument10 pagesCase Study Based On: Cloud Deployment and Service Delivery ModelsNikunj JenaNo ratings yet
- U5 SCMDocument48 pagesU5 SCMbhathrinaathan16No ratings yet
- Cloud Strategy Workshop Building a Cloud Strategy to Meet Your Business GoalsDocument55 pagesCloud Strategy Workshop Building a Cloud Strategy to Meet Your Business GoalsJose SerranoNo ratings yet
- Factors Shaping The Future of Cloud ComputingDocument92 pagesFactors Shaping The Future of Cloud ComputingSteve FrancisNo ratings yet
- CIS Tomcat 10 Benchmark v1.0.0 PDFDocument169 pagesCIS Tomcat 10 Benchmark v1.0.0 PDFIván López - InnovattiaNo ratings yet
- Cloud ComputingDocument1 pageCloud Computingharpreetchawla7No ratings yet
- Hadoop BI Questions and Answers - Trenovision PDFDocument32 pagesHadoop BI Questions and Answers - Trenovision PDFManjula SuryakanthNo ratings yet
- Bahir Dar University School of Computing Department of Computer ScienceDocument20 pagesBahir Dar University School of Computing Department of Computer Scienceayenew dessalengNo ratings yet
- Cloud Computing PPT PresentationDocument12 pagesCloud Computing PPT Presentationsartaj ahmadNo ratings yet
- PTCL Data Centre FinalDocument32 pagesPTCL Data Centre FinalZohaib Chachar100% (2)
- Cloud Computing in A Military ContextDocument25 pagesCloud Computing in A Military Contextpercybhai031No ratings yet
- Magic Quadrant For Enterprise Integration Platform As A ServiceDocument37 pagesMagic Quadrant For Enterprise Integration Platform As A ServiceAlexNo ratings yet
- 1.01 - Guardium Data Protection OverviewDocument20 pages1.01 - Guardium Data Protection OverviewishtiaqNo ratings yet
- Datasheet AVEVA Historian 04-20.PDF - Coredownload.inlineDocument5 pagesDatasheet AVEVA Historian 04-20.PDF - Coredownload.inlineMINH NHHUT LUUNo ratings yet
- Virtualization:: Virtualization Can Be Achieved at Different Levels. If You Consider Hardware, The Organization NeedsDocument6 pagesVirtualization:: Virtualization Can Be Achieved at Different Levels. If You Consider Hardware, The Organization Needskalpana.gangwarNo ratings yet
- Arcserve SaaS Backup Flyer - Use Wording Eg. ImmutableDocument2 pagesArcserve SaaS Backup Flyer - Use Wording Eg. ImmutableDen ClarkNo ratings yet
- Oracle Cloud Project Management For PartnersDocument38 pagesOracle Cloud Project Management For PartnersHsie HsuanNo ratings yet
- VMware Partner Connect Program GuideDocument61 pagesVMware Partner Connect Program Guidegabriel100% (2)
- Business Plan Executive Summary ExampleDocument2 pagesBusiness Plan Executive Summary ExampleDavid WorrellNo ratings yet
- Power Bi FundamentalsDocument379 pagesPower Bi FundamentalsShailja Sheetal100% (1)
- MongoDB As A ServiceDocument20 pagesMongoDB As A ServiceSuhas KawleNo ratings yet
- IBM Power Systems Virtual Server Level 2 Quiz - Attempt ReviewDocument16 pagesIBM Power Systems Virtual Server Level 2 Quiz - Attempt ReviewCh3Ro100% (5)
- Value CreationDocument2 pagesValue CreationSabin GurungNo ratings yet
- Microsoft Dynamics ERP Licensing GuideDocument20 pagesMicrosoft Dynamics ERP Licensing GuideHussam El Deen El FaramawiNo ratings yet
- Mach Si Member Application Form-2021!10!18 - V7Document4 pagesMach Si Member Application Form-2021!10!18 - V7JoseNo ratings yet
- 2024 CPA Information Systems & Controls (ISC) Mock Exam AnswersDocument52 pages2024 CPA Information Systems & Controls (ISC) Mock Exam AnswerscraigsappletreeNo ratings yet
- FinalsDocument67 pagesFinalsBela100% (1)
- Getting Started With Oracle CloudDocument69 pagesGetting Started With Oracle CloudJean CarlosNo ratings yet
- Emc It' Journey To The Private Cloud: Applications and Cloud ExperienceDocument14 pagesEmc It' Journey To The Private Cloud: Applications and Cloud Experienceskyadav35No ratings yet
- Application of Cloud ComputingDocument17 pagesApplication of Cloud ComputingPreetika SastryNo ratings yet