You might also like
- Canbus DtasheetDocument22 pagesCanbus Dtasheetsefa7171No ratings yet
- Cloud Design PatternsDocument236 pagesCloud Design PatternsAraxhiel100% (3)
- AR650, AR1600, AR6100, AR6200, and AR6300 Hardware DescriptionDocument570 pagesAR650, AR1600, AR6100, AR6200, and AR6300 Hardware DescriptionjuharieNo ratings yet
- Google Cloud Platform for Data Engineering: From Beginner to Data Engineer using Google Cloud PlatformFrom EverandGoogle Cloud Platform for Data Engineering: From Beginner to Data Engineer using Google Cloud PlatformRating: 5 out of 5 stars5/5 (1)
- 8 Steps For Migrating Existing Applications To MicroservicesDocument44 pages8 Steps For Migrating Existing Applications To MicroservicesRizwan AhmedNo ratings yet
- Wedding Management DatabaseDocument19 pagesWedding Management DatabaseNavdeep ManiNo ratings yet
- VTU Exam Question Paper With Solution of 18CS72 Big Data and Analytics Feb-2022-Dr. v. VijayalakshmiDocument25 pagesVTU Exam Question Paper With Solution of 18CS72 Big Data and Analytics Feb-2022-Dr. v. VijayalakshmiWWE ROCKERSNo ratings yet
- Exchange PowershellDocument6 pagesExchange PowershellchakibNo ratings yet
- The Ultimate Guide to Unlocking the Full Potential of Cloud Services: Tips, Recommendations, and Strategies for SuccessFrom EverandThe Ultimate Guide to Unlocking the Full Potential of Cloud Services: Tips, Recommendations, and Strategies for SuccessNo ratings yet
- Supporting Multi Data Stores Applications in Cloud EnvironmentsDocument14 pagesSupporting Multi Data Stores Applications in Cloud EnvironmentsVigneshInfotechNo ratings yet
- Optimizing Information Leakage in Multicloud Storage ServicesDocument27 pagesOptimizing Information Leakage in Multicloud Storage ServicesKiran Maramulla67% (3)
- Data Modeling Foundations for Data ScienceDocument50 pagesData Modeling Foundations for Data ScienceHENDRA GUNAWANNo ratings yet
- Ensuring Cloud Data Storage Security with Distributed Verification and Error LocalizationDocument5 pagesEnsuring Cloud Data Storage Security with Distributed Verification and Error Localizationdevangana1991No ratings yet
- 07 Automated Data MigrationDocument9 pages07 Automated Data MigrationpabloNo ratings yet
- Methodology For Solving Data Portability in Cloud Information Technology EssayDocument4 pagesMethodology For Solving Data Portability in Cloud Information Technology EssayKarthik KrishnamurthiNo ratings yet
- Cloud Database Performance and SecurityDocument9 pagesCloud Database Performance and SecurityP SankarNo ratings yet
- List The Main Categories of DataDocument10 pagesList The Main Categories of Datasramalingam288953No ratings yet
- Enhancing Scalability in Big Data and Cloud ComputingDocument7 pagesEnhancing Scalability in Big Data and Cloud Computingprayas jhariyaNo ratings yet
- Analysis of Open Source Computing Techniques & Comparison On Cloud-Based ERPDocument7 pagesAnalysis of Open Source Computing Techniques & Comparison On Cloud-Based ERPInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Ijettcs 2013 08 24 111Document8 pagesIjettcs 2013 08 24 111International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- The Growing Enormous of Big Data StorageDocument6 pagesThe Growing Enormous of Big Data StorageEddy ManurungNo ratings yet
- What Is Cloud Computing? Cloud Computing Is The Use of Computing Resources (Hardware andDocument74 pagesWhat Is Cloud Computing? Cloud Computing Is The Use of Computing Resources (Hardware andSanda MounikaNo ratings yet
- Distribution, Data, Deployment: Software Architecture Convergence in Big Data SystemsDocument14 pagesDistribution, Data, Deployment: Software Architecture Convergence in Big Data SystemschebinegaNo ratings yet
- Latest Research Papers On Distributed DatabaseDocument5 pagesLatest Research Papers On Distributed Databasettdqgsbnd100% (1)
- Distributed Query Processing +Document19 pagesDistributed Query Processing +Prashant DeepNo ratings yet
- S4: Distributed Stream Computing PlatformDocument8 pagesS4: Distributed Stream Computing PlatformOtávio CarvalhoNo ratings yet
- Introduction To Smart SystemsDocument22 pagesIntroduction To Smart Systemsapi-321004552No ratings yet
- Senger Et Al-2016-Concurrency and Computation Practice and ExperienceDocument4 pagesSenger Et Al-2016-Concurrency and Computation Practice and ExperienceMahalingam RamaswamyNo ratings yet
- Hadoop - MapReduceDocument51 pagesHadoop - MapReducedangtranNo ratings yet
- Zeldovich - Relational CloudDocument7 pagesZeldovich - Relational CloudVăn Hoàng NguyễnNo ratings yet
- Dbms Project Report: Agricultural Sales Management SystemDocument20 pagesDbms Project Report: Agricultural Sales Management System2K18/ME/202 SAURAV BANSALNo ratings yet
- Data Management Iot Bigdata Cloud ScadaDocument11 pagesData Management Iot Bigdata Cloud ScadatrivediurvishNo ratings yet
- Framing The Future of Information Systems in Afghan DynamicsDocument4 pagesFraming The Future of Information Systems in Afghan DynamicsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- DevOps Patterns To Scale Web Applications Using Cloud ServicesDocument10 pagesDevOps Patterns To Scale Web Applications Using Cloud ServicesDaniel CukierNo ratings yet
- Sharna Cs DoneDocument15 pagesSharna Cs Donebalaji xeroxNo ratings yet
- Object-oriented database management systems (ODBMS) explainedDocument5 pagesObject-oriented database management systems (ODBMS) explainedvedmcaNo ratings yet
- Unit 4Document38 pagesUnit 4Dharmik SuchakNo ratings yet
- Cloud Computing Security and PrivacyDocument57 pagesCloud Computing Security and PrivacyMahesh PalaniNo ratings yet
- Critical Analysis of Ecm Applications in The Clouds: A Case StudyDocument12 pagesCritical Analysis of Ecm Applications in The Clouds: A Case StudyAnonymous Gl4IRRjzNNo ratings yet
- Db4o Reference JavaDocument252 pagesDb4o Reference JavaEdson BtNo ratings yet
- Big Data Dan Cloud ComputingDocument19 pagesBig Data Dan Cloud ComputingKarenNo ratings yet
- Big Data in Cloud Computing A Literature ReviewDocument7 pagesBig Data in Cloud Computing A Literature ReviewSalil NaikNo ratings yet
- Performance Evaluation of Iot Data Management Using Mongodb Versus Mysql Databases in Different Cloud EnvironmentsDocument13 pagesPerformance Evaluation of Iot Data Management Using Mongodb Versus Mysql Databases in Different Cloud EnvironmentsMD. KAMRUZZAMAN LEIONNo ratings yet
- Research Inventy: International Journal of Engineering and ScienceDocument5 pagesResearch Inventy: International Journal of Engineering and ScienceinventyNo ratings yet
- Zarmina DDB Ass#2Document10 pagesZarmina DDB Ass#2Meena JadoonNo ratings yet
- MapReduce in Hadoop: What is MapReduce? Scalable Processing of Big DataDocument11 pagesMapReduce in Hadoop: What is MapReduce? Scalable Processing of Big DataASHISH CHAUDHARYNo ratings yet
- Management of Data Intensive Application Workflow in Cloud ComputingDocument4 pagesManagement of Data Intensive Application Workflow in Cloud ComputingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Project Report On DBMS ProjectDocument22 pagesProject Report On DBMS Projectpankaj singhNo ratings yet
- Towards Heterogeneous Multimedia Information Systems: The Garlic ApproachDocument8 pagesTowards Heterogeneous Multimedia Information Systems: The Garlic ApproachbetsinghNo ratings yet
- CH 09Document38 pagesCH 09Violeta GjiniNo ratings yet
- Cloud Analytics Ability To Design, Build, Secure, and Maintain Analytics Solutions On The CloudDocument5 pagesCloud Analytics Ability To Design, Build, Secure, and Maintain Analytics Solutions On The CloudEditor IJTSRDNo ratings yet
- Thesis On Distributed Database SystemDocument8 pagesThesis On Distributed Database Systemvetepuwej1z3100% (2)
- Business Applications Exam Prep PL-900: Microsoft Power Platform FundamentalsDocument165 pagesBusiness Applications Exam Prep PL-900: Microsoft Power Platform FundamentalsGiancarlo HerreraNo ratings yet
- Chap 2 Emerging Database LandscapeDocument10 pagesChap 2 Emerging Database LandscapeSwatiJadhavNo ratings yet
- Open Source Cloud Computing Tools: A Case Study With A Weather ApplicationDocument7 pagesOpen Source Cloud Computing Tools: A Case Study With A Weather Applicationvinaykumargupta1992No ratings yet
- Security Issues in Big Data Cloud ComputingDocument12 pagesSecurity Issues in Big Data Cloud ComputingJobi VijayNo ratings yet
- Open Source Cloud Computing Tools - A Case Study With A Weather ApplicationDocument7 pagesOpen Source Cloud Computing Tools - A Case Study With A Weather Applicationgjkumar_mcaNo ratings yet
- 8-9 Spatial Data MaintenanceDocument12 pages8-9 Spatial Data Maintenancekevin.kipchoge18No ratings yet
- 10gen-MongoDB Operations Best Practices 2.6Document26 pages10gen-MongoDB Operations Best Practices 2.6vector090No ratings yet
- Achieving Secure, Scalable and Fine-Grained Data Access Control in Cloud ComputingDocument47 pagesAchieving Secure, Scalable and Fine-Grained Data Access Control in Cloud Computingpssumi2No ratings yet
- de-220121-180442-M.Tech - M.Pharm Supply Project Thesis Uploading Notification Jan-2022Document3 pagesde-220121-180442-M.Tech - M.Pharm Supply Project Thesis Uploading Notification Jan-2022VigneshInfotechNo ratings yet
- An Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorDocument39 pagesAn Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorVigneshInfotechNo ratings yet
- Preparation of Papers in Two-Column Format For Publications of IEIDocument3 pagesPreparation of Papers in Two-Column Format For Publications of IEIVigneshInfotechNo ratings yet
- Saitej Resume DoneDocument2 pagesSaitej Resume DoneVigneshInfotechNo ratings yet
- STUDENT Name:: Mundada Vinay Kumar EmailDocument2 pagesSTUDENT Name:: Mundada Vinay Kumar EmailVigneshInfotechNo ratings yet
- Employee school visit report with school detailsDocument4 pagesEmployee school visit report with school detailsVigneshInfotechNo ratings yet
- CV SaberDocument3 pagesCV SaberVigneshInfotechNo ratings yet
- Numbers: 5 and 6 Digits: AnswersDocument37 pagesNumbers: 5 and 6 Digits: AnswersVigneshInfotechNo ratings yet
- Data Leakage DetectionDocument26 pagesData Leakage DetectionVigneshInfotechNo ratings yet
- Ambedkar Jagarla: Email: Ambedkarj010Document2 pagesAmbedkar Jagarla: Email: Ambedkarj010VigneshInfotechNo ratings yet
- 2 MasDocument29 pages2 MasVigneshInfotechNo ratings yet
- FCDocument5 pagesFCVigneshInfotechNo ratings yet
- Low Power - Area Efficient Multiplexer Restructuring For VLSI ImplementationDocument8 pagesLow Power - Area Efficient Multiplexer Restructuring For VLSI ImplementationVigneshInfotechNo ratings yet
- Your Family and NeighbourhoodDocument30 pagesYour Family and NeighbourhoodVigneshInfotechNo ratings yet
- 24-Mar-2019, CC, BZA - KZJDocument2 pages24-Mar-2019, CC, BZA - KZJVigneshInfotechNo ratings yet
- 1 5177093672394555706Document2 pages1 5177093672394555706VigneshInfotechNo ratings yet
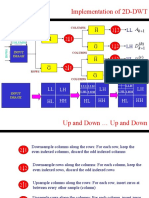
- Implementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHDocument4 pagesImplementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHVigneshInfotechNo ratings yet
- 1 EngDocument32 pages1 EngVigneshInfotechNo ratings yet
- Image Denoising Using Wavelet Shrinkage TechniquesDocument60 pagesImage Denoising Using Wavelet Shrinkage TechniquesVigneshInfotechNo ratings yet
- Discrete Wavelet TransformDocument10 pagesDiscrete Wavelet TransformVigneshInfotechNo ratings yet
- Matlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'Document1 pageMatlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'VigneshInfotechNo ratings yet
- Project Documentation Guidelines - ECE - JITS2013Document4 pagesProject Documentation Guidelines - ECE - JITS2013VigneshInfotechNo ratings yet
- FCDocument1 pageFCVigneshInfotechNo ratings yet
- 2 Evs PDFDocument39 pages2 Evs PDFVigneshInfotechNo ratings yet
- Performance analysis of BPSK and DPSK under Nakagami fadingDocument5 pagesPerformance analysis of BPSK and DPSK under Nakagami fadingVigneshInfotechNo ratings yet
- Final Wifi 2Document87 pagesFinal Wifi 2VigneshInfotechNo ratings yet
- Design and Implementation of Area-Optimized AES Based On FPGADocument4 pagesDesign and Implementation of Area-Optimized AES Based On FPGAVigneshInfotechNo ratings yet
- Error Detection and Data Recovery for Motion Estimation TestingDocument3 pagesError Detection and Data Recovery for Motion Estimation TestingVigneshInfotechNo ratings yet
- A New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmDocument8 pagesA New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmVigneshInfotechNo ratings yet
- 5and 6Document15 pages5and 6VigneshInfotechNo ratings yet
- Mil-Std-1553 Tutorial WP Gft711aDocument38 pagesMil-Std-1553 Tutorial WP Gft711aCourtney DavisNo ratings yet
- Clearscada Getting StartedDocument28 pagesClearscada Getting StartedErhan KırcımanoğluNo ratings yet
- FCPIT File (For PTU B.Tech 1st Yr Students)Document105 pagesFCPIT File (For PTU B.Tech 1st Yr Students)Cutie83% (6)
- Feature Satip4Document6 pagesFeature Satip4Alexander WieseNo ratings yet
- NAS Drive User ManualDocument59 pagesNAS Drive User ManualCristian ScarlatNo ratings yet
- Telecom Billing System: Pragallath P.SDocument16 pagesTelecom Billing System: Pragallath P.SPragallath PSNo ratings yet
- Multiprogramming Operating System - JavatpointDocument3 pagesMultiprogramming Operating System - JavatpointAvin MannNo ratings yet
- Release NotespdfDocument3 pagesRelease NotespdfRogin Dave SerranoNo ratings yet
- Soyal Communication Protocol AR-725EDocument25 pagesSoyal Communication Protocol AR-725ESenki AlfonzNo ratings yet
- How To Convert PDF Files To Word Processing Files (RFT)Document3 pagesHow To Convert PDF Files To Word Processing Files (RFT)BCCCSNo ratings yet
- How To Install and Configure PANAgentDocument23 pagesHow To Install and Configure PANAgentd0re1No ratings yet
- MCQ - MPMCDocument9 pagesMCQ - MPMCRanganayaki RamkumarNo ratings yet
- C Compiler Apk - Hanapin Sa GoogleDocument1 pageC Compiler Apk - Hanapin Sa GoogleDenzel T. LanzaderasNo ratings yet
- GIG IA CapabilitiesDocument605 pagesGIG IA CapabilitieskrebsonsecurityNo ratings yet
- SCCPCH Concept ImplementationDocument11 pagesSCCPCH Concept ImplementationMuhammad Bilal JunaidNo ratings yet
- Modbus TCP PN CPU EnglishDocument64 pagesModbus TCP PN CPU Englishgeorgel1605No ratings yet
- 68 HC11 ManualDocument36 pages68 HC11 ManualГеорги МончевNo ratings yet
- SMSC Call FlowDocument3 pagesSMSC Call FlowMaharshi MahrshiNo ratings yet
- RS485 PDFDocument3 pagesRS485 PDFLaurentiu Iacob100% (2)
- Template of PEMRA LicenseDocument8 pagesTemplate of PEMRA LicenseMuhammad AliNo ratings yet
- Cell Splitting: Microwave Wireless Network PlanningDocument5 pagesCell Splitting: Microwave Wireless Network PlanningPraveen SehgalNo ratings yet
- Juniper - Mist AP41 Access PointDocument4 pagesJuniper - Mist AP41 Access PointBullzeye StrategyNo ratings yet
- Consumer segments focus on families, teens and singlesDocument24 pagesConsumer segments focus on families, teens and singlesMarinoiu MarianNo ratings yet
- SICAM PAS - Overview - Final - ENDocument11 pagesSICAM PAS - Overview - Final - ENAldo Bona HasudunganNo ratings yet
- Publish Your Documents Upload Documents: Unlock Your Documents by Putting Them On ScribdDocument18 pagesPublish Your Documents Upload Documents: Unlock Your Documents by Putting Them On Scribdm.bakrNo ratings yet
- Ofdm For Wireless Communications Systems PDFDocument2 pagesOfdm For Wireless Communications Systems PDFKatieNo ratings yet
- Cissp Security ArchitectureDocument20 pagesCissp Security Architecturefern12No ratings yet