You might also like
- BarraOne for Multi-Asset Risk ManagementDocument2 pagesBarraOne for Multi-Asset Risk ManagementSujit PotnisNo ratings yet
- "Risk On - Risk Off" - How A Paradigm Is BornDocument19 pages"Risk On - Risk Off" - How A Paradigm Is BorntniravNo ratings yet
- Man AHL Analysis CTA Intelligence - On Trend-Following CTAs and Quant Multi-Strategy Funds ENG 20140901Document1 pageMan AHL Analysis CTA Intelligence - On Trend-Following CTAs and Quant Multi-Strategy Funds ENG 20140901kevinNo ratings yet
- DCM For LSEDocument14 pagesDCM For LSEAlbert TsouNo ratings yet
- Credit Quant SightDocument26 pagesCredit Quant SightmarioturriNo ratings yet
- UBS Business Plan - Stategic Planning and Financing Basis - Model For Generating A Business Plan - (UBS AG) PDFDocument26 pagesUBS Business Plan - Stategic Planning and Financing Basis - Model For Generating A Business Plan - (UBS AG) PDFQuantDev-MNo ratings yet
- Agencies JPMDocument18 pagesAgencies JPMbonefish212No ratings yet
- JPM Flows Liquidity 2016-10-07 2145906Document18 pagesJPM Flows Liquidity 2016-10-07 2145906chaotic_pandemoniumNo ratings yet
- Nomura CDS Primer 12may04Document12 pagesNomura CDS Primer 12may04Ethan Sun100% (1)
- Volatility Exchange-Traded Notes - Curse or CureDocument25 pagesVolatility Exchange-Traded Notes - Curse or CurelastkraftwagenfahrerNo ratings yet
- Lehman Brothers 2001 DerivativesDocument46 pagesLehman Brothers 2001 DerivativesFloored100% (3)
- The Complete Overview of The Value Line Investment SurveyDocument24 pagesThe Complete Overview of The Value Line Investment SurveytarookmaktuNo ratings yet
- Saxo Asset Allocation - 20090804Document5 pagesSaxo Asset Allocation - 20090804Trading Floor100% (2)
- WK 5 BF Tutorial Qns and Solns PDFDocument6 pagesWK 5 BF Tutorial Qns and Solns PDFIlko KacarskiNo ratings yet
- E-mini Stock Index Futures: An IntroductionDocument13 pagesE-mini Stock Index Futures: An IntroductionEric MarlowNo ratings yet
- 2008 DB Fixed Income Outlook (12!14!07)Document107 pages2008 DB Fixed Income Outlook (12!14!07)STNo ratings yet
- Can Alpha Be Captured by Risk Premia PublicDocument25 pagesCan Alpha Be Captured by Risk Premia PublicDerek FultonNo ratings yet
- Libor Market Model Specification and CalibrationDocument29 pagesLibor Market Model Specification and CalibrationGeorge LiuNo ratings yet
- Understanding RecessionsDocument3 pagesUnderstanding RecessionsVariant Perception Research100% (1)
- Funds Transfer PricingDocument11 pagesFunds Transfer PricingValério GonçalvesNo ratings yet
- CLS Currency Program Briefing BookDocument24 pagesCLS Currency Program Briefing BookNitin NagpureNo ratings yet
- qCIO Global Macro Hedge Fund Strategy - November 2014Document31 pagesqCIO Global Macro Hedge Fund Strategy - November 2014Q.M.S Advisors LLCNo ratings yet
- Corporate Banking Summer Internship ProgramDocument2 pagesCorporate Banking Summer Internship ProgramPrince JainNo ratings yet
- Currency OptionsDocument6 pagesCurrency OptionsDealCurry100% (1)
- Technical Analysis - UBSDocument59 pagesTechnical Analysis - UBSTigis Sutigis100% (1)
- A User's Guide To SOFR: The Alternative Reference Rates Committee April 2019Document21 pagesA User's Guide To SOFR: The Alternative Reference Rates Committee April 2019rajat.panda2672100% (1)
- BarclaysDocument30 pagesBarclaysw_fib100% (1)
- Earnings Theory PaperDocument64 pagesEarnings Theory PaperPrateek SabharwalNo ratings yet
- Riding The Yield Curve 1663880194Document81 pagesRiding The Yield Curve 1663880194Daniel PeñaNo ratings yet
- Dynamics of Swaps SpreadsDocument32 pagesDynamics of Swaps SpreadsAkshat Kumar SinhaNo ratings yet
- 1 1 Investment Management Interview QuestionsDocument3 pages1 1 Investment Management Interview Questionsdeepu9989No ratings yet
- Intro To Credit Risk Exposure MeasurementDocument36 pagesIntro To Credit Risk Exposure MeasurementALNo ratings yet
- Equities Business Overview PresentationDocument28 pagesEquities Business Overview Presentationsinwha321No ratings yet
- Daily Market Report and OutlookDocument2 pagesDaily Market Report and OutlookVikash GoelNo ratings yet
- Risk Management StrategiesDocument30 pagesRisk Management StrategiesevalpalNo ratings yet
- Understanding Debt and Currency CrisesDocument2 pagesUnderstanding Debt and Currency CrisesVariant Perception Research0% (1)
- CMT Level 1 DefsDocument21 pagesCMT Level 1 DefsIxjnxNo ratings yet
- Credit Suisse Brochure SP Flexible enDocument23 pagesCredit Suisse Brochure SP Flexible ensh2k2kNo ratings yet
- Easy Volatility Investing StrategiesDocument33 pagesEasy Volatility Investing StrategiescttfsdaveNo ratings yet
- Structured Products OverviewDocument7 pagesStructured Products OverviewAnkit GoelNo ratings yet
- Barclays Weekly Options Report Vols Die HardDocument10 pagesBarclays Weekly Options Report Vols Die HardVitaly ShatkovskyNo ratings yet
- Index Variance Arbitrage: Arbitraging Component CorrelationDocument39 pagesIndex Variance Arbitrage: Arbitraging Component Correlationcclaudel09No ratings yet
- Equity Derivatives PDFDocument38 pagesEquity Derivatives PDFwowebooksNo ratings yet
- Spreads Versus Spread VolDocument14 pagesSpreads Versus Spread VolMatt WallNo ratings yet
- Pricing Financial Derivatives with Local Volatility ModelsDocument114 pagesPricing Financial Derivatives with Local Volatility ModelsTze ShaoNo ratings yet
- HSBC - Finding Optimal Value in Real Yield 2013-12-13Document16 pagesHSBC - Finding Optimal Value in Real Yield 2013-12-13Ji YanbinNo ratings yet
- 807512Document24 pages807512Shweta SrivastavaNo ratings yet
- Drawbacks of Pearson CorrelationDocument39 pagesDrawbacks of Pearson CorrelationZiyaNo ratings yet
- CBOT-Understanding BasisDocument26 pagesCBOT-Understanding BasisIshan SaneNo ratings yet
- Understanding Eurodollar FuturesDocument24 pagesUnderstanding Eurodollar FuturesOrestis :. KonstantinidisNo ratings yet
- Use Duration and Convexity To Measure RiskDocument4 pagesUse Duration and Convexity To Measure RiskSreenesh PaiNo ratings yet
- Measuring Investment Returns of Portfolios Containing Futures and OptionsDocument9 pagesMeasuring Investment Returns of Portfolios Containing Futures and Optionskusi786No ratings yet
- Volatility Radar: Profit From Low Vol and High SkewDocument14 pagesVolatility Radar: Profit From Low Vol and High SkewTze ShaoNo ratings yet
- Nomura Strategy 03 11Document106 pagesNomura Strategy 03 11Thiago PalaiaNo ratings yet
- CAPM Approach Beta Is Dead or AliveDocument23 pagesCAPM Approach Beta Is Dead or AliveKazim KhanNo ratings yet
- Structured Financial Product A Complete Guide - 2020 EditionFrom EverandStructured Financial Product A Complete Guide - 2020 EditionNo ratings yet
- Financial Markets, Banking, and Monetary PolicyFrom EverandFinancial Markets, Banking, and Monetary PolicyRating: 5 out of 5 stars5/5 (1)
- Exchange Rate Determination Puzzle: Long Run Behavior and Short Run DynamicsFrom EverandExchange Rate Determination Puzzle: Long Run Behavior and Short Run DynamicsNo ratings yet
- China Inflation Monitor (Jan 16) PDFDocument2 pagesChina Inflation Monitor (Jan 16) PDFzpmellaNo ratings yet
- China Economics Update - RMB, Outflows (Jan 16) PDFDocument1 pageChina Economics Update - RMB, Outflows (Jan 16) PDFzpmellaNo ratings yet
- Global Policy Uncertainty DataDocument6 pagesGlobal Policy Uncertainty DatazpmellaNo ratings yet
- Weekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, July 2018 (Week 4)Document2 pagesWeekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, July 2018 (Week 4)zpmellaNo ratings yet
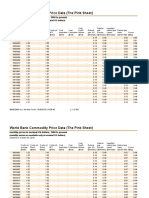
- CMOHistorical Data MonthlyDocument295 pagesCMOHistorical Data MonthlyzpmellaNo ratings yet
- Commodities Weekly Wrap (8th Jan 2016) PDFDocument5 pagesCommodities Weekly Wrap (8th Jan 2016) PDFzpmellaNo ratings yet
- China Economics Update - Growth Vs Markets (Jan 16) PDFDocument1 pageChina Economics Update - Growth Vs Markets (Jan 16) PDFzpmellaNo ratings yet
- Weekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, July 2018 (Week 4)Document2 pagesWeekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, July 2018 (Week 4)zpmellaNo ratings yet
- Weekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, by Region, August 2018 (Week 4)Document3 pagesWeekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, by Region, August 2018 (Week 4)zpmellaNo ratings yet
- US Policy Uncertainty DataDocument24 pagesUS Policy Uncertainty DatazpmellaNo ratings yet
- Weekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, June 2018 (Week 5)Document2 pagesWeekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, June 2018 (Week 5)zpmellaNo ratings yet
- MZMSLDocument15 pagesMZMSLzpmellaNo ratings yet
- Weekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, August 2018 (Week 4)Document2 pagesWeekly Farmgate, Wholesale and Retail Prices of Palay, Rice and Corn, August 2018 (Week 4)zpmellaNo ratings yet
- US Historical EPU DataDocument66 pagesUS Historical EPU DatazpmellaNo ratings yet
- Xurpas Inc - 2018 Gis08162018180414 PDFDocument10 pagesXurpas Inc - 2018 Gis08162018180414 PDFzpmellaNo ratings yet
- INDPRODocument22 pagesINDPRODan McNo ratings yet
- Xurpas Inc. 2016 Annual Report PDFDocument165 pagesXurpas Inc. 2016 Annual Report PDFzpmellaNo ratings yet
- 2016 STORM Flex Report-Min PDFDocument10 pages2016 STORM Flex Report-Min PDFzpmellaNo ratings yet
- 1QFS 2017 Final PDFDocument77 pages1QFS 2017 Final PDFzpmellaNo ratings yet
- Cover Sheet: Company NameDocument79 pagesCover Sheet: Company NamezpmellaNo ratings yet
- Xis 2Q2016 17Q Final PDFDocument70 pagesXis 2Q2016 17Q Final PDFzpmellaNo ratings yet
- Cover Sheet: Company NameDocument74 pagesCover Sheet: Company NamezpmellaNo ratings yet
- Xurpas - 2Q 2018 Consolidated FS FINAL PDFDocument84 pagesXurpas - 2Q 2018 Consolidated FS FINAL PDFzpmellaNo ratings yet
- 1Q 2018 Xurpas Analyst Briefing PDFDocument3 pages1Q 2018 Xurpas Analyst Briefing PDFzpmellaNo ratings yet
- Xurpas - 2Q 2018 Consolidated FS FINAL PDFDocument84 pagesXurpas - 2Q 2018 Consolidated FS FINAL PDFzpmellaNo ratings yet
- 2Q 2018 Xurpas Analyst Briefing Transcript PDFDocument6 pages2Q 2018 Xurpas Analyst Briefing Transcript PDFzpmellaNo ratings yet
- Xurpas Inc. SEC 18-A PDFDocument5 pagesXurpas Inc. SEC 18-A PDFzpmellaNo ratings yet
- 3rd Sem 4 Electrical Engineering Syllabus For WB PolytechnicDocument35 pages3rd Sem 4 Electrical Engineering Syllabus For WB PolytechnicParthasarothi SikderNo ratings yet
- Newton's Second Law AnalysisDocument2 pagesNewton's Second Law AnalysisJamiel CatapangNo ratings yet
- CBSE Class 12 Chemistry Practice Paper 2017Document5 pagesCBSE Class 12 Chemistry Practice Paper 2017rishi017No ratings yet
- Engineering Graphics Assignment Long Questions Unit-IDocument2 pagesEngineering Graphics Assignment Long Questions Unit-Ishaikamaan10jgs18080006No ratings yet
- CAPA, Root Cause Analysis, and Risk ManagementDocument53 pagesCAPA, Root Cause Analysis, and Risk ManagementAbhijitNo ratings yet
- Internet Homework Problems on Time Studies and Standard TimesDocument2 pagesInternet Homework Problems on Time Studies and Standard TimesRohit WadhwaniNo ratings yet
- MIT2 29S15 Lecture10Document26 pagesMIT2 29S15 Lecture10Ihab OmarNo ratings yet
- Determination of The Identity of An Unknown LiquidDocument4 pagesDetermination of The Identity of An Unknown LiquidJoshuaNo ratings yet
- MasterProgramming - in - BCA C Programing Assignment 2021Document79 pagesMasterProgramming - in - BCA C Programing Assignment 2021Debnath SahaNo ratings yet
- Moment of InertiaDocument7 pagesMoment of InertiaNazir AbdulmajidNo ratings yet
- Basic Calculus-Q3-Module-2Document23 pagesBasic Calculus-Q3-Module-2macgigaonlinestore100% (1)
- Isometric ProjectionsDocument22 pagesIsometric ProjectionsSakshiNo ratings yet
- C Algorithms For Real-Time DSP - EMBREEDocument125 pagesC Algorithms For Real-Time DSP - EMBREELuiz Carlos da SilvaNo ratings yet
- NAVY DSSC Exam Past Questions and AnswersDocument7 pagesNAVY DSSC Exam Past Questions and AnswersEmmanuel AdegokeNo ratings yet
- Czitrom1999 PDFDocument7 pagesCzitrom1999 PDFHarutyun AlaverdyanNo ratings yet
- Practical PhysicsDocument329 pagesPractical Physicsgangstaq875% (8)
- Quantitative Finance: 1 Probability and StatisticsDocument2 pagesQuantitative Finance: 1 Probability and StatisticsVidaup40No ratings yet
- Amplitude Curves in ABAQUS CAEDocument12 pagesAmplitude Curves in ABAQUS CAELogicAndFacts ChannelNo ratings yet
- Solns 9Document66 pagesSolns 9ramprakash_rampelliNo ratings yet
- EconomicsDocument49 pagesEconomicsRebinNo ratings yet
- CbotDocument6 pagesCbottarunaNo ratings yet
- PIC Microcontroller USB Multi-Channel Data Acquisition and Control SystemDocument21 pagesPIC Microcontroller USB Multi-Channel Data Acquisition and Control SystemY-Morilla MaNo ratings yet
- OR Research for Business DecisionsDocument55 pagesOR Research for Business DecisionsSalmonNo ratings yet
- Birational Geometry Caucher Birkar PDFDocument35 pagesBirational Geometry Caucher Birkar PDFhuangrj9No ratings yet
- Na5 Service Manual Bargraph LumelDocument64 pagesNa5 Service Manual Bargraph LumelCusbac BacauNo ratings yet
- MT Chapter 11Document4 pagesMT Chapter 11WuileapNo ratings yet
- Me53 Design of Machine Elements L T P CDocument2 pagesMe53 Design of Machine Elements L T P CajithjkingsNo ratings yet
- Smiley Face TricksDocument2 pagesSmiley Face Tricksapi-2221425760% (1)
- Creating FunctionsDocument6 pagesCreating FunctionsCatalina AchimNo ratings yet
- Paper 1Document14 pagesPaper 1KhushilNo ratings yet