You might also like
- Flujo información genética bacterianaDocument35 pagesFlujo información genética bacterianachebetomx100% (1)
- Reticulo Endoplasmático LisoDocument4 pagesReticulo Endoplasmático LisoDel Valle CarlitosNo ratings yet
- Cinética y Mecanismos Del Edema Celular Isosmótico Mediado Por Amoníaco y Amonio en Células de NeuroblastomaDocument147 pagesCinética y Mecanismos Del Edema Celular Isosmótico Mediado Por Amoníaco y Amonio en Células de NeuroblastomavictorMB100% (1)
- LisosomasDocument4 pagesLisosomasViKtor M. GarciaNo ratings yet
- Historia de La CélulaDocument7 pagesHistoria de La CélulaAlender Jesus Vargas TovarNo ratings yet
- Ante Bio MicroDocument84 pagesAnte Bio MicroClaudia Hernandez100% (1)
- Semana 6 Biologia PPT Ciclo CelularDocument55 pagesSemana 6 Biologia PPT Ciclo Celularhector maita100% (1)
- Mecanismos de Señalizacion de Insulina, Glucolisis, GluconeogenesisDocument19 pagesMecanismos de Señalizacion de Insulina, Glucolisis, Gluconeogenesisxlz100% (1)
- Organelos CitoplasmáticoDocument16 pagesOrganelos CitoplasmáticoAlexandra Bernedo UndaNo ratings yet
- Mitoc. oxidación biológicaDocument45 pagesMitoc. oxidación biológicaYadilka ViñolesNo ratings yet
- Bioquimica MedicaDocument21 pagesBioquimica MedicaMayerly FVNo ratings yet
- LisosomasDocument2 pagesLisosomasKarla Peláez GalánNo ratings yet
- LisosomasDocument14 pagesLisosomasAndrea0% (1)
- Clase LisosomasDocument19 pagesClase LisosomasJC MedinaNo ratings yet
- Retículo Endoplásmico Pi MZVDocument29 pagesRetículo Endoplásmico Pi MZVCool BoyLVNo ratings yet
- Lisosomas, peroxisomas y Glioxisomas: descubrimiento y funcionesDocument14 pagesLisosomas, peroxisomas y Glioxisomas: descubrimiento y funcionesJose E. MirandaNo ratings yet
- LISOSOMASDocument4 pagesLISOSOMASSara GilNo ratings yet
- Replicacion, Transcripción Y Traducción.: Hugo Peña PiscoyaDocument60 pagesReplicacion, Transcripción Y Traducción.: Hugo Peña PiscoyaCarlosNo ratings yet
- Practico Nº 3Document3 pagesPractico Nº 3Maria Rodriguez Olivera100% (1)
- 13) Reticulo EndoplasmicoDocument27 pages13) Reticulo EndoplasmicoPerla Gutiérrez RogelNo ratings yet
- Diapositiva de Reticulo Endoplasmatico LisoDocument8 pagesDiapositiva de Reticulo Endoplasmatico LisoDaniela Monserrat Olarte SalazarNo ratings yet
- Duplicacion de ADNDocument60 pagesDuplicacion de ADNmusicart30008394No ratings yet
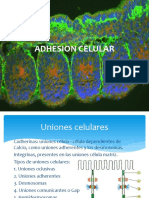
- Adhesion CelularDocument30 pagesAdhesion CelularBeto HdzNo ratings yet
- Presentación Duplicación ADNDocument18 pagesPresentación Duplicación ADNRicar RLNo ratings yet
- ANEXO 1. CÉLULA EUCARIOTA CorregidoDocument2 pagesANEXO 1. CÉLULA EUCARIOTA CorregidoabNo ratings yet
- Retículo Endoplasmático RugosoDocument4 pagesRetículo Endoplasmático RugosoC H Cruz CaballeroNo ratings yet
- Transcripción y Traduccion 01Document24 pagesTranscripción y Traduccion 01Ricardo Medina MedicinaNo ratings yet
- Lisosomas, Peroxisomas y RibosomaDocument16 pagesLisosomas, Peroxisomas y RibosomaJuan MoralesNo ratings yet
- Mitosis MeiosisDocument51 pagesMitosis MeiosisValentina GrilliNo ratings yet
- Tema 7 Uniones CelularesDocument6 pagesTema 7 Uniones CelularesDavid Molina LópezNo ratings yet
- Biologia SangreDocument7 pagesBiologia SangreVictorhugo Snider Manuyama EscuderoNo ratings yet
- Mecanismos de Reparación Del DnaDocument10 pagesMecanismos de Reparación Del Dnalaura torresNo ratings yet
- Sistemas membranales celulares: Retículo endoplasmáticoDocument9 pagesSistemas membranales celulares: Retículo endoplasmáticoEnrique Ochoa0% (1)
- Guía003 - Organización Subcelular - Biología Celular Lab OratorioDocument11 pagesGuía003 - Organización Subcelular - Biología Celular Lab Oratorioapi-3710186100% (7)
- Ciclo Celular Mitosis MeiosisDocument17 pagesCiclo Celular Mitosis MeiosisALEX RADEMAKERNo ratings yet
- Mitosis y MeiosisDocument8 pagesMitosis y MeiosisAnonymous zl6Gi8No ratings yet
- Aparato de Golgi Lisosomas y VacuolasDocument43 pagesAparato de Golgi Lisosomas y VacuolasscribdenesimoNo ratings yet
- Guía de Estudio Organelos CitoplasmáticosDocument2 pagesGuía de Estudio Organelos CitoplasmáticosMarco Mapt100% (1)
- Ciclo Del Ácido Citrico KrebsDocument50 pagesCiclo Del Ácido Citrico KrebsAde RendónNo ratings yet
- Organelas celulares y estructura nuclearDocument51 pagesOrganelas celulares y estructura nuclearJanet Palomino OrtizNo ratings yet
- Organelos Citoplasmaticos MaterialDocument6 pagesOrganelos Citoplasmaticos Materialjohanna yanchatipanNo ratings yet
- Cuadro de PunnetDocument5 pagesCuadro de PunnetMaricela LópezNo ratings yet
- Retículo Endoplasmático LisoDocument2 pagesRetículo Endoplasmático LisoRenato RenatoNo ratings yet
- Funciones Del AmpcDocument3 pagesFunciones Del AmpcRaulNo ratings yet
- El Aparato de Golgi: Estructura, Funciones y Procesos SecretoresDocument34 pagesEl Aparato de Golgi: Estructura, Funciones y Procesos SecretoresMoisés J. Duran CanevaroNo ratings yet
- 9 Teórica Tráfico de Proteínas PDFDocument74 pages9 Teórica Tráfico de Proteínas PDFIrene CarballoNo ratings yet
- Primera Clase de BiologiaDocument28 pagesPrimera Clase de BiologiaLuxa Valverde ChicllaNo ratings yet
- Celula CitoplasmaDocument131 pagesCelula CitoplasmaFreideth Villa100% (2)
- Mutaciones ResumenDocument7 pagesMutaciones ResumenCristianGuardadoNo ratings yet
- Tema 6. LA MADURACIÓN DE LAS PROTEÍNASDocument5 pagesTema 6. LA MADURACIÓN DE LAS PROTEÍNASNataly Garcia Navas0% (1)
- Metabolismo CatabolismoDocument33 pagesMetabolismo CatabolismoFrancis A. Batarse0% (1)
- La Mitocondria y La Respiración CelularDocument31 pagesLa Mitocondria y La Respiración CelularMarco Antonio Morales OsorioNo ratings yet
- Meiosis Mitosis y FecundacionDocument12 pagesMeiosis Mitosis y FecundacionEzequiel Ananias Caceres RojasNo ratings yet
- Esquema Del Ciclo CelularDocument5 pagesEsquema Del Ciclo CelularAntonio Servin GarciaNo ratings yet
- Libro - La Evolucion de Los Seres Vivos PDFDocument24 pagesLibro - La Evolucion de Los Seres Vivos PDFJavier RafNo ratings yet
- U2 4 - Biología 1Document6 pagesU2 4 - Biología 1Gabby CorralesNo ratings yet
- Informe N°4Document14 pagesInforme N°4sarai chucuyaNo ratings yet
- Informe s10 Bioinformática Gc1Document20 pagesInforme s10 Bioinformática Gc1Carbajo MayrelyNo ratings yet
- Bioinformatica Aplicado A La Medicina VeterinariaDocument18 pagesBioinformatica Aplicado A La Medicina VeterinariaJose Abelardo QuiñonesNo ratings yet
- Introducción A La BioinformáticaDocument8 pagesIntroducción A La BioinformáticaFrancesc Caralt RafecasNo ratings yet
- Unidad2 SeriesdeFourier PDFDocument74 pagesUnidad2 SeriesdeFourier PDFRosy GtzNo ratings yet
- Transformada de LaplaceDocument74 pagesTransformada de LaplaceRosy GtzNo ratings yet
- Unidad2 Transferenciadematerialgeneticoyseleccionbacteriana PDFDocument44 pagesUnidad2 Transferenciadematerialgeneticoyseleccionbacteriana PDFRosy GtzNo ratings yet
- Ingeniería en biotecnología: Balance de materia y energía en planta de tratamientoDocument4 pagesIngeniería en biotecnología: Balance de materia y energía en planta de tratamientoRosy GtzNo ratings yet
- Bbme U1 A1 RogpDocument5 pagesBbme U1 A1 RogpRosy GtzNo ratings yet
- Bbme U2 Ea RogpDocument8 pagesBbme U2 Ea RogpRosy Gtz100% (1)
- Bbme U2 A2 RogpDocument7 pagesBbme U2 A2 RogpRosy Gtz100% (2)
- Bbme U1 Ea RogpDocument8 pagesBbme U1 Ea RogpRosy GtzNo ratings yet
- Bbme U2 A1 RogpDocument9 pagesBbme U2 A1 RogpRosy Gtz100% (3)
- Bfde U1 Atr RogpDocument3 pagesBfde U1 Atr RogpRosy Gtz100% (2)
- Bbme U1 A1 RogpDocument5 pagesBbme U1 A1 RogpRosy GtzNo ratings yet
- Bbme U1 A2 RogpDocument3 pagesBbme U1 A2 RogpRosy Gtz100% (1)
- Qan - U1 - Ea - RogpDocument11 pagesQan - U1 - Ea - RogpRosy GtzNo ratings yet
- Bfiq U1 Ea RogpDocument7 pagesBfiq U1 Ea RogpRosy GtzNo ratings yet
- Act. 1 FIQUIDocument4 pagesAct. 1 FIQUIRosy GtzNo ratings yet
- Atr U2 RogmDocument1 pageAtr U2 RogmRosy GtzNo ratings yet
- Act. 2Document4 pagesAct. 2Rosy GtzNo ratings yet
- Manual de Selección, Uso y Mantenimiento de CompresoresDocument298 pagesManual de Selección, Uso y Mantenimiento de CompresoresEDINSON85% (26)
- Autoevaluación 3Document2 pagesAutoevaluación 3Rosy GtzNo ratings yet
- Qan U2 A4 RogpDocument12 pagesQan U2 A4 RogpRosy GtzNo ratings yet
- Actividad IntegradoraDocument1 pageActividad IntegradoraRosy GtzNo ratings yet
- Bfiq U1 A3 GproDocument9 pagesBfiq U1 A3 GproRosy GtzNo ratings yet
- Fi U2 Oti RogpDocument1 pageFi U2 Oti RogpRosy GtzNo ratings yet
- Atr U1 RogmDocument1 pageAtr U1 RogmRosy GtzNo ratings yet
- Fi U1 Ea RogpDocument8 pagesFi U1 Ea RogpRosy GtzNo ratings yet
- Atr U3 RogmDocument2 pagesAtr U3 RogmRosy GtzNo ratings yet
- Eb U3 Ea RogpDocument15 pagesEb U3 Ea RogpRosy GtzNo ratings yet
- Atr U4 RogmDocument2 pagesAtr U4 RogmRosy GtzNo ratings yet
- Autoevaluación IVDocument2 pagesAutoevaluación IVRosy GtzNo ratings yet
- Ácidos nucleicos y nucleoproteínasDocument93 pagesÁcidos nucleicos y nucleoproteínasAshley ReyNo ratings yet
- Tema 1.1 CélulaDocument37 pagesTema 1.1 CélulakarmosnavcNo ratings yet
- Biología Molecular.1 (2)Document8 pagesBiología Molecular.1 (2)Julian NeiraNo ratings yet
- Biociencias I - Práctica #3 La CélulaDocument20 pagesBiociencias I - Práctica #3 La CélulaLIBRERIA UNIVERSALNo ratings yet
- Cómo estamos formados a nivel celularDocument3 pagesCómo estamos formados a nivel celularMaycol Callan HernandezNo ratings yet
- Biologia 1 PDFDocument84 pagesBiologia 1 PDFOscar Lemus RamírezNo ratings yet
- Guía #1 Funciones Del Nucleo Grado Septimo Ciencias 2Document4 pagesGuía #1 Funciones Del Nucleo Grado Septimo Ciencias 2edward ortegaNo ratings yet
- Macromoléculas: proteínas, polisacáridos y ADNDocument33 pagesMacromoléculas: proteínas, polisacáridos y ADNKamilitta TapiaNo ratings yet
- Guía 1 Noveno CNDocument8 pagesGuía 1 Noveno CNWikus Van de MerweNo ratings yet
- Actividad 3 - Diseño de Un Esquema de La Célula Utilizando Como Recurso PowerPoint y Sus Herramientas de AnimaciónDocument3 pagesActividad 3 - Diseño de Un Esquema de La Célula Utilizando Como Recurso PowerPoint y Sus Herramientas de Animacióneulalia100% (3)
- Bol. Semana 5Document4 pagesBol. Semana 5MARILU PAUCAR CHACÓNNo ratings yet
- GUIA No. 1 GENÉTICA Y BIOTECNOLOGÍADocument15 pagesGUIA No. 1 GENÉTICA Y BIOTECNOLOGÍAsandraNo ratings yet
- Super Repaso 1 - 4Document8 pagesSuper Repaso 1 - 4B123No ratings yet
- Biologia Primera ParteDocument23 pagesBiologia Primera ParteNatalieNo ratings yet
- Informe 4Document18 pagesInforme 4SunNo ratings yet
- Biologia VegetalDocument17 pagesBiologia VegetalFelipe C.RNo ratings yet
- Resumen Base Molecular y Fisico Quimica de La VidaDocument11 pagesResumen Base Molecular y Fisico Quimica de La Vidaines montmarNo ratings yet
- EUCITOSDocument49 pagesEUCITOSMilagros AguilarNo ratings yet
- BioquímicaDocument6 pagesBioquímicamaria chaconNo ratings yet
- Lineal de Unos Pocos Nucleótidos Diferentes.: Opción ADocument9 pagesLineal de Unos Pocos Nucleótidos Diferentes.: Opción AMaximiliano Luis LoveraNo ratings yet
- Ácidos NucleicosDocument4 pagesÁcidos NucleicosAndrea CardenaNo ratings yet
- 21OblBiologiaCelular PDFDocument5 pages21OblBiologiaCelular PDFaguivaldNo ratings yet
- Grupo 5 - La CélulaDocument7 pagesGrupo 5 - La CélulaISABEL PATRICIA VILCAHUAMAN PONCENo ratings yet
- Mapas Conceptual de BiologíaDocument1 pageMapas Conceptual de BiologíaAndrews GarciaNo ratings yet
- Codones de TerminoDocument79 pagesCodones de TerminoYazmin OsorioNo ratings yet
- 2DO BGU TEXTO BIOLOGIA Páginas 27,36,47 48,56,59Document6 pages2DO BGU TEXTO BIOLOGIA Páginas 27,36,47 48,56,59BryanNo ratings yet
- Diferencias entre célula eucariota y procariotaDocument19 pagesDiferencias entre célula eucariota y procariotaChocolatesDoñaMaruNo ratings yet
- Guía - 1-Biologia 8 La CelulaDocument10 pagesGuía - 1-Biologia 8 La CelulaGloria Isabel Aguirre ParedesNo ratings yet
- Células SeparataDocument4 pagesCélulas SeparataDiego Renee Rodas GomezNo ratings yet
- Practica O4 de Biología y Educación Ambiental 2021-IDocument9 pagesPractica O4 de Biología y Educación Ambiental 2021-IHarold Misael Bruno SilvaNo ratings yet