You might also like
- Mathews Paul G. Design of Experiments With MINITAB PDFDocument521 pagesMathews Paul G. Design of Experiments With MINITAB PDFFernando Chavarria100% (2)
- HUL Valuation Using DCFDocument14 pagesHUL Valuation Using DCFShuvam KoleyNo ratings yet
- Analysis of Variance (ANOVA)Document18 pagesAnalysis of Variance (ANOVA)Vivay Salazar100% (6)
- Unit Iv Design of ExperimentsDocument34 pagesUnit Iv Design of ExperimentsMathioli Senthil0% (1)
- Introduction To ForecastingDocument22 pagesIntroduction To ForecastingJoe Di NapoliNo ratings yet
- Flotation TestworkDocument36 pagesFlotation TestworkJoseph Ramirez100% (1)
- Mass Balancing McGillDocument20 pagesMass Balancing McGillMag Arias100% (4)
- BS 812 - 1 Testing AggregatesDocument12 pagesBS 812 - 1 Testing AggregatesAmenaw MulunehNo ratings yet
- 1.6.2 RCBD (Hale) - Supp ReadingDocument13 pages1.6.2 RCBD (Hale) - Supp ReadingTeflon SlimNo ratings yet
- Topic6 ReadingDocument13 pagesTopic6 ReadingJeannetteNo ratings yet
- Topic 6. Randomized Complete Block Design (RCBD)Document20 pagesTopic 6. Randomized Complete Block Design (RCBD)Teflon SlimNo ratings yet
- Topic 6. Two-Way Designs: Randomized Complete Block DesignDocument18 pagesTopic 6. Two-Way Designs: Randomized Complete Block DesignmaleticjNo ratings yet
- RCBD lecture on randomized complete block designsDocument20 pagesRCBD lecture on randomized complete block designsEsamul HaqNo ratings yet
- Control of Experimental Error: Blocking and Randomized Block DesignDocument24 pagesControl of Experimental Error: Blocking and Randomized Block DesignAl Malik Delmo MamintalNo ratings yet
- Topic 6. Randomized Complete Block Design (RCBD)Document19 pagesTopic 6. Randomized Complete Block Design (RCBD)maleticjNo ratings yet
- TwoWay ANOVA CalculationsDocument8 pagesTwoWay ANOVA Calculationsdarren mapanooNo ratings yet
- Randomized Complete Block Design AnalysisDocument26 pagesRandomized Complete Block Design AnalysisEsamul HaqNo ratings yet
- 465 Fwm310aDocument35 pages465 Fwm310aDave DunsinNo ratings yet
- Randomized Blocks Design - Description - Layout - Analysis - Advantages and DisadvantagesDocument3 pagesRandomized Blocks Design - Description - Layout - Analysis - Advantages and Disadvantagesrubi singhNo ratings yet
- FEM 3004 - Lab 8 - 24.12.20Document35 pagesFEM 3004 - Lab 8 - 24.12.20AINA NADHIRAH BINTI A ROZEY / UPMNo ratings yet
- Randomized Block DesignDocument8 pagesRandomized Block DesignDhona أزلف AquilaniNo ratings yet
- Analysis of Variance (Anova) Part 2 Two-Way Anova ReplicationDocument18 pagesAnalysis of Variance (Anova) Part 2 Two-Way Anova ReplicationFarrukh JamilNo ratings yet
- Unit 10 Randomised Block Design: StructureDocument16 pagesUnit 10 Randomised Block Design: Structurejv YashwanthNo ratings yet
- Randomized Block Design: ModelDocument4 pagesRandomized Block Design: ModelRaShika RashiNo ratings yet
- Analysis of Variance Analysis of Variance: Steps For One Way ClassificationDocument2 pagesAnalysis of Variance Analysis of Variance: Steps For One Way ClassificationNathaniel EsguerraNo ratings yet
- LSD With CDDocument7 pagesLSD With CDKiven ArdenoNo ratings yet
- Two-way ANOVA of cattle weight gainsDocument4 pagesTwo-way ANOVA of cattle weight gainspounise2000No ratings yet
- Analysis of Variance-Two Way ClassificationDocument4 pagesAnalysis of Variance-Two Way Classificationsri harsha namburiNo ratings yet
- Classification of Experimental DesignsDocument26 pagesClassification of Experimental DesignsSHEETAL SINGHNo ratings yet
- 15 Anova-IiDocument23 pages15 Anova-IiSOBHIT SNo ratings yet
- Phy2049 f2019 Re Exam1 PDFDocument6 pagesPhy2049 f2019 Re Exam1 PDFHaleyNo ratings yet
- Analyzing agricultural experiments with RCBD and Latin square designsDocument32 pagesAnalyzing agricultural experiments with RCBD and Latin square designsSyra Salvador NaridoNo ratings yet
- U5 2-RandomizedBlockDesignsDocument21 pagesU5 2-RandomizedBlockDesignsMuhammad Naeem IqbalNo ratings yet
- Unit 5-Two MarksDocument4 pagesUnit 5-Two MarkslokeshnathNo ratings yet
- Randomized Block DesignDocument7 pagesRandomized Block DesignPurani SwethaNo ratings yet
- 1 The Randomized Block DesignDocument5 pages1 The Randomized Block DesignadibNo ratings yet
- Experimental Designs for Agricultural ResearchDocument28 pagesExperimental Designs for Agricultural ResearchZeeshan UsmaniNo ratings yet
- Latin Square Design Stat-301&stat-512Document7 pagesLatin Square Design Stat-301&stat-512Raksha SandilyaNo ratings yet
- Balanced Incomplete BlockDocument4 pagesBalanced Incomplete BlockItalo GranatoNo ratings yet
- Analysis of VarianceDocument36 pagesAnalysis of Variancezain3kmdNo ratings yet
- Lab9 Split Plot Design and Its RelativesDocument12 pagesLab9 Split Plot Design and Its Relativesjorbeloco100% (1)
- Lec24 PDFDocument32 pagesLec24 PDFEsamul HaqNo ratings yet
- 13 - Principles of Experimental Designs - CRDDocument28 pages13 - Principles of Experimental Designs - CRDRuth TradingsNo ratings yet
- Ejm Lattice DesignsDocument21 pagesEjm Lattice DesignsMaría C. SanabriamNo ratings yet
- 2015 Hw1011 KeyDocument5 pages2015 Hw1011 KeyPiNo ratings yet
- Chapter 3 HunterDocument21 pagesChapter 3 HunterOsama AnatyNo ratings yet
- CH 04Document10 pagesCH 04Wiwid MurdanyNo ratings yet
- 2.-A Population Geneticist Wants To Test The Significance of The Differences inDocument10 pages2.-A Population Geneticist Wants To Test The Significance of The Differences inTeflon SlimNo ratings yet
- Anova Two WayDocument35 pagesAnova Two WaysakshitaNo ratings yet
- RCBDDocument55 pagesRCBDHamza KhanNo ratings yet
- Anova 2Document29 pagesAnova 2Mohit GuptaNo ratings yet
- RCBDDocument18 pagesRCBDpinky_0083No ratings yet
- ANOVA Table for CRD with Equal ReplicationDocument7 pagesANOVA Table for CRD with Equal ReplicationmanojNo ratings yet
- Hypotest FDocument9 pagesHypotest FPriscilla ChantalNo ratings yet
- Design of ExperimentDocument19 pagesDesign of ExperimentelakkiyaNo ratings yet
- Other Experimental Designs: Randomized Block Design Latin Square Design Repeated Measures DesignDocument84 pagesOther Experimental Designs: Randomized Block Design Latin Square Design Repeated Measures DesignSaras AgrawalNo ratings yet
- 11 Analisis Ragam (Varian-2)Document15 pages11 Analisis Ragam (Varian-2)sudahkuliahNo ratings yet
- SBE - 11e Ch13b DOE and Analysis of Variance DOE ANOVADocument24 pagesSBE - 11e Ch13b DOE and Analysis of Variance DOE ANOVAjohn brownNo ratings yet
- Randomized Complete Block Design (RCBDDocument9 pagesRandomized Complete Block Design (RCBDEsamul HaqNo ratings yet
- Completely Randomized Design With and Without SubsamplesDocument22 pagesCompletely Randomized Design With and Without SubsamplesKen KleinNo ratings yet
- RCBD Revised NotesDocument30 pagesRCBD Revised NotesFernando JamesNo ratings yet
- Exam - 2015 - Spring SolutionDocument4 pagesExam - 2015 - Spring SolutionSushil AcharyaNo ratings yet
- Topic 7. Double Grouping. Latin Squares (ST&D 9.10-9.15)Document8 pagesTopic 7. Double Grouping. Latin Squares (ST&D 9.10-9.15)maleticjNo ratings yet
- Randamized Block NotedDocument5 pagesRandamized Block NotedyagnasreeNo ratings yet
- Reviews in Computational ChemistryFrom EverandReviews in Computational ChemistryAbby L. ParrillNo ratings yet
- Copper Zinc Tin Sulfide-Based Thin-Film Solar CellsFrom EverandCopper Zinc Tin Sulfide-Based Thin-Film Solar CellsKentaro ItoNo ratings yet
- Gen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableDocument5 pagesGen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableTeflon SlimNo ratings yet
- Regional Hybrid TrialDocument8 pagesRegional Hybrid TrialTeflon SlimNo ratings yet
- R Codes Germinate Seed Data AnalysisDocument1 pageR Codes Germinate Seed Data AnalysisTeflon SlimNo ratings yet
- Hybrid Maize Yield and Trait DataDocument46 pagesHybrid Maize Yield and Trait DataTeflon SlimNo ratings yet
- Ideal Tester STR-BA1057Document7 pagesIdeal Tester STR-BA1057Teflon SlimNo ratings yet
- Interploidy Hybridization in Sympatric Zones The FormationDocument14 pagesInterploidy Hybridization in Sympatric Zones The FormationTeflon SlimNo ratings yet
- File Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunDocument48 pagesFile Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunTeflon SlimNo ratings yet
- GGE Biplot of GCA Stability AnalysisDocument24 pagesGGE Biplot of GCA Stability AnalysisTeflon SlimNo ratings yet
- Table 2Document1 pageTable 2Teflon SlimNo ratings yet
- Combined Diallel-W DataDocument703 pagesCombined Diallel-W DataTeflon SlimNo ratings yet
- Results FileDocument159 pagesResults FileTeflon SlimNo ratings yet
- Table 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Document1 pageTable 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Teflon SlimNo ratings yet
- Obs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldDocument292 pagesObs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldTeflon SlimNo ratings yet
- Combining Ability of Extra-Early White Inbreds Final DraftDocument57 pagesCombining Ability of Extra-Early White Inbreds Final DraftTeflon SlimNo ratings yet
- Additive NonadditiveDocument1 pageAdditive NonadditiveTeflon SlimNo ratings yet
- Figure 5Document1 pageFigure 5Teflon SlimNo ratings yet
- SCA Effects of Grain Yield in Maize HybridsDocument1 pageSCA Effects of Grain Yield in Maize HybridsTeflon SlimNo ratings yet
- Inbred Lines Evaluated in Nigeria, 2011.: MaizeDocument1 pageInbred Lines Evaluated in Nigeria, 2011.: MaizeTeflon SlimNo ratings yet
- Correlation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitDocument23 pagesCorrelation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitTeflon SlimNo ratings yet
- Table 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationDocument1 pageTable 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationTeflon SlimNo ratings yet
- Responses To Reviewers' Comments CommentDocument4 pagesResponses To Reviewers' Comments CommentTeflon SlimNo ratings yet
- Data Analysis - Practical SessionDocument12 pagesData Analysis - Practical SessionTeflon SlimNo ratings yet
- Figure 1Document1 pageFigure 1Teflon SlimNo ratings yet
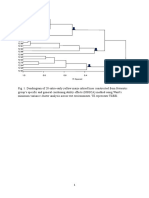
- Dendrogram of 20 extra-early yellow maize inbred lines constructed from HSGCA methodDocument1 pageDendrogram of 20 extra-early yellow maize inbred lines constructed from HSGCA methodTeflon SlimNo ratings yet
- Figure 4Document1 pageFigure 4Teflon SlimNo ratings yet
- Figure 2Document1 pageFigure 2Teflon SlimNo ratings yet
- Ba0727ik DataDocument12 pagesBa0727ik DataTeflon SlimNo ratings yet
- Practical Session - Sample DataDocument21 pagesPractical Session - Sample DataTeflon SlimNo ratings yet
- Anhu 12083Document8 pagesAnhu 12083Teflon SlimNo ratings yet
- MRP Biscuit factors influencing preferenceDocument1 pageMRP Biscuit factors influencing preference...No ratings yet
- Minitab Problem 6.1Document2 pagesMinitab Problem 6.1Varsha MalviyaNo ratings yet
- 1 Introduction To State EstimationDocument96 pages1 Introduction To State EstimationHarish BabuNo ratings yet
- Analysis of Hydrostatic Force On Submerged and Partially Submerged Plane Surface Using Tecquipment H314Document4 pagesAnalysis of Hydrostatic Force On Submerged and Partially Submerged Plane Surface Using Tecquipment H314Lester JayNo ratings yet
- Mathematica Laboratories For Mathematical StatisticsDocument26 pagesMathematica Laboratories For Mathematical Statisticshammoudeh13No ratings yet
- Model Evaluation MetricsDocument21 pagesModel Evaluation MetricsYoussef MissaouiNo ratings yet
- APPC Mock EXAM Review StudentDocument16 pagesAPPC Mock EXAM Review StudenthindusaarthiNo ratings yet
- Learn Data Scoence LearnbayDocument8 pagesLearn Data Scoence LearnbayVinay SathyanarayanNo ratings yet
- CE205 Interpolation CurvefittingDocument35 pagesCE205 Interpolation CurvefittingRubaiya Kabir OrchiNo ratings yet
- MBA 2nd Sem Exam PaperDocument24 pagesMBA 2nd Sem Exam PaperkeyurNo ratings yet
- Analysis of VarianceDocument18 pagesAnalysis of Variancemia farrowNo ratings yet
- Investigating The Effect of Machining Parameters On Surface RoughnessDocument7 pagesInvestigating The Effect of Machining Parameters On Surface RoughnessIAEME PublicationNo ratings yet
- Chapter 8 HeteroskedasticityDocument52 pagesChapter 8 HeteroskedasticitytanNo ratings yet
- Probability & Statistics PracticalsDocument28 pagesProbability & Statistics PracticalsJeevan PandeyNo ratings yet
- Lab Report Importance and FormatDocument4 pagesLab Report Importance and FormatAziz SomroNo ratings yet
- The Role of Nigerian Stock Exchange in Capital Formation in Nigeria (Chapters 4 and 5Document14 pagesThe Role of Nigerian Stock Exchange in Capital Formation in Nigeria (Chapters 4 and 5Newman EnyiokoNo ratings yet
- Pengaruh Manajemen Perubahan Terhadap Organisasi Pembelajaran Serta Dampaknya Terhadap Kinerja Pegawai Pada PT. KAI (Persero) Daop II BandungDocument16 pagesPengaruh Manajemen Perubahan Terhadap Organisasi Pembelajaran Serta Dampaknya Terhadap Kinerja Pegawai Pada PT. KAI (Persero) Daop II BandungFaisal HamdiNo ratings yet
- Development of Demand Forecasting Models For Improved Customer Service in Nigeria Soft Drink Industry - Case of Coca-Cola Company EnuguDocument8 pagesDevelopment of Demand Forecasting Models For Improved Customer Service in Nigeria Soft Drink Industry - Case of Coca-Cola Company EnuguijsretNo ratings yet
- Tutorial 5 - Linear Regression S and ADocument8 pagesTutorial 5 - Linear Regression S and AFirdaus LasnangNo ratings yet
- Unit-III (Data Analytics)Document15 pagesUnit-III (Data Analytics)bhavya.shivani1473No ratings yet
- BMIS360-AnswerKeys Revision SheetDocument13 pagesBMIS360-AnswerKeys Revision SheetMtvc LbNo ratings yet
- Assignment Week 9-QuestionsDocument3 pagesAssignment Week 9-QuestionsRetno Ajeng Anissa WidiatriNo ratings yet
- SPSSDocument30 pagesSPSShimadri.roy8469No ratings yet
- Urban Density and Travel TimesDocument10 pagesUrban Density and Travel TimesNCKH IPURDNo ratings yet
- International Journal of Mathematics and Statistics Invention (IJMSI)Document17 pagesInternational Journal of Mathematics and Statistics Invention (IJMSI)inventionjournalsNo ratings yet