You might also like
- A VARIETY IN EVOLUTION - BradleyDocument2 pagesA VARIETY IN EVOLUTION - Bradleybradley gansataoNo ratings yet
- Detectio AutomationDocument14 pagesDetectio AutomationsfarithaNo ratings yet
- A Gender Based Study of Tagging Behavior in Twitter: (Evandrocunha, Magno, Virgilio, Mgoncalv, Fabricio) @Document2 pagesA Gender Based Study of Tagging Behavior in Twitter: (Evandrocunha, Magno, Virgilio, Mgoncalv, Fabricio) @Wendel TeixeiraNo ratings yet
- T Gov PanagiotisDocument13 pagesT Gov Panagiotisaseyadi2030No ratings yet
- Detecting Spammers on Twitter Using Machine LearningDocument9 pagesDetecting Spammers on Twitter Using Machine LearningsupriyabnNo ratings yet
- Gender Classification of Twitter Data Based On Textual Meta-Attributes ExtractionDocument10 pagesGender Classification of Twitter Data Based On Textual Meta-Attributes ExtractionVishal PoonachaNo ratings yet
- Who Gives A Tweet? Evaluating Microblog Content Value: Paul André, Michael S. Bernstein, Kurt LutherDocument4 pagesWho Gives A Tweet? Evaluating Microblog Content Value: Paul André, Michael S. Bernstein, Kurt Luthermisafirem3798No ratings yet
- Credibility Analysis For Tweets Written in Turkish by A Hybrid MethodDocument8 pagesCredibility Analysis For Tweets Written in Turkish by A Hybrid MethodliezelleannNo ratings yet
- Mobile Tweets More EgocentricDocument2 pagesMobile Tweets More EgocentricCatleah Zamora20% (5)
- Reaserch PaperDocument25 pagesReaserch PaperMhyls MayabasonNo ratings yet
- What Is Twitter, A Social Network or A News MediaDocument10 pagesWhat Is Twitter, A Social Network or A News MediaAlex Poma PancayaNo ratings yet
- Twitter Uncertainty 5 13 2021Document14 pagesTwitter Uncertainty 5 13 2021Cristina VenegasNo ratings yet
- Sentiment Analysis and Influence Tracking Using TwitterDocument8 pagesSentiment Analysis and Influence Tracking Using TwitterIjarcsee JournalNo ratings yet
- Robust Sentiment Detection On Twitter From Biased and Noisy DataDocument9 pagesRobust Sentiment Detection On Twitter From Biased and Noisy DataEss Kay EssNo ratings yet
- mln2018 PDFDocument11 pagesmln2018 PDFKheir eddine DaouadiNo ratings yet
- The geo-temporal demographics of Twitter usage in LondonDocument35 pagesThe geo-temporal demographics of Twitter usage in LondonHarry NugrahaNo ratings yet
- Less Is More - How Demographic Sample Weights Can Improve Public Opinion Estimates Based On Twitter DataDocument12 pagesLess Is More - How Demographic Sample Weights Can Improve Public Opinion Estimates Based On Twitter DataShay PalachyNo ratings yet
- Sentiment Analysis On TwitterDocument7 pagesSentiment Analysis On TwitterarmanghouriNo ratings yet
- Twitter Sentiment Analysis Using EmoticonsDocument7 pagesTwitter Sentiment Analysis Using EmoticonsMarita Miranda BustamanteNo ratings yet
- Information Search and Retrieval in MicroblogsDocument42 pagesInformation Search and Retrieval in MicroblogsFlavio58ITNo ratings yet
- The Effects Cognitive Approach of Personality Expression: Results in The LiteratureDocument5 pagesThe Effects Cognitive Approach of Personality Expression: Results in The LiteratureMajoysa MagpileNo ratings yet
- Facebook Vs Twitter ProjectDocument7 pagesFacebook Vs Twitter ProjectBharat MistryNo ratings yet
- Twitter User Classification Using Metadata FeaturesDocument9 pagesTwitter User Classification Using Metadata FeaturesKheir eddine DaouadiNo ratings yet
- 2010 WWW TwitterDocument10 pages2010 WWW Twitterrobmac3No ratings yet
- Comparative Study of RumourDocument25 pagesComparative Study of RumourkritheedeviNo ratings yet
- Machine Learning Project: "Social Media Sentimental AnalysisDocument15 pagesMachine Learning Project: "Social Media Sentimental AnalysisNavya DNo ratings yet
- Twitter OdtDocument4 pagesTwitter OdtsweetsureshNo ratings yet
- A Comparative Study of Users Microbloggi PDFDocument12 pagesA Comparative Study of Users Microbloggi PDFThiên ÂnNo ratings yet
- State of The Twittersphere: June 2009Document9 pagesState of The Twittersphere: June 2009api-26006336No ratings yet
- Online Human-Bot InteractionsDocument10 pagesOnline Human-Bot InteractionsMarian AldescuNo ratings yet
- Social MediaDocument8 pagesSocial MediaHanilen CatamaNo ratings yet
- 10 1 1 433 6263 PDFDocument10 pages10 1 1 433 6263 PDFV SilvaNo ratings yet
- Twitter Mining For Discovery, Prediction and Causality: Applications and MethodologiesDocument21 pagesTwitter Mining For Discovery, Prediction and Causality: Applications and Methodologiesu5647No ratings yet
- Analysis of Twitter Usage in London, Paris, and New York CityDocument7 pagesAnalysis of Twitter Usage in London, Paris, and New York CityMadalina Andreea MiuNo ratings yet
- Dorsey TestimonyDocument11 pagesDorsey TestimonyCNBC.comNo ratings yet
- Using Lists To Measure Homophily On Twitter: Jeon Hyung Kang Kristina LermanDocument7 pagesUsing Lists To Measure Homophily On Twitter: Jeon Hyung Kang Kristina LermansameendraNo ratings yet
- Social Media and Political Leaders: An Exploratory AnalysisDocument15 pagesSocial Media and Political Leaders: An Exploratory AnalysisEve AthanasekouNo ratings yet
- The Blogosphere-Colliding With Social and Mainstream MediaDocument11 pagesThe Blogosphere-Colliding With Social and Mainstream MediaTheonlyone01No ratings yet
- Fake News SynopsisDocument10 pagesFake News Synopsisbiraa9128No ratings yet
- Uses and Gratifications of Twitter An ExaminationDocument32 pagesUses and Gratifications of Twitter An Examinationauditstream00No ratings yet
- Investigación Sobre El Algoritmo de TwitterDocument27 pagesInvestigación Sobre El Algoritmo de TwitterClarin.comNo ratings yet
- Asymmetries of Men and Women in Selecting Partner: Haluk O. Bingol and Omer BasarDocument7 pagesAsymmetries of Men and Women in Selecting Partner: Haluk O. Bingol and Omer BasarAydın SakarNo ratings yet
- Twitter Study Compares Language DifferencesDocument14 pagesTwitter Study Compares Language DifferencesvcautinNo ratings yet
- S U R J S S: Indh Niversity Esearch Ournal (Cience Eries)Document6 pagesS U R J S S: Indh Niversity Esearch Ournal (Cience Eries)adsNo ratings yet
- Twitter Sentiment Analytic P-1Document17 pagesTwitter Sentiment Analytic P-1Rishabh JhaNo ratings yet
- Opinion Retrieval in Twitter: Zhunchen Luo Miles Osborne Ting WangDocument4 pagesOpinion Retrieval in Twitter: Zhunchen Luo Miles Osborne Ting WangNeri David MartinezNo ratings yet
- Microblogging Inside and Outside The Workplace: Kate Ehrlich, N. Sadat ShamiDocument9 pagesMicroblogging Inside and Outside The Workplace: Kate Ehrlich, N. Sadat Shamiapi-25918538No ratings yet
- The future of actionable social media measurement depends on data quality standardsDocument4 pagesThe future of actionable social media measurement depends on data quality standardsRavi Kiran NavuduriNo ratings yet
- Mobile Tweets Differ in Linguistic Styles and Emotional ContentDocument3 pagesMobile Tweets Differ in Linguistic Styles and Emotional ContentIvy Mie SagangNo ratings yet
- Semantifying Twitter with the influenceTracker ontologyDocument8 pagesSemantifying Twitter with the influenceTracker ontologyjbshirkNo ratings yet
- Age and Gender Identification in Social MediaDocument8 pagesAge and Gender Identification in Social MediaarifNo ratings yet
- Twitter Use by The U.S. CongressDocument10 pagesTwitter Use by The U.S. Congress杨紫寒No ratings yet
- Jurnal AnalisisDocument8 pagesJurnal AnalisisramliNo ratings yet
- Social Media: How To Use Social Media Marketing To Grow Your BusinessFrom EverandSocial Media: How To Use Social Media Marketing To Grow Your BusinessNo ratings yet
- Twitter Power (Review and Analysis of Comm and Burge's Book)From EverandTwitter Power (Review and Analysis of Comm and Burge's Book)No ratings yet
- Media Relations Handbook for Government, Associations, Nonprofits, and Elected Officials, 2eFrom EverandMedia Relations Handbook for Government, Associations, Nonprofits, and Elected Officials, 2eNo ratings yet
- Smart HealthCare by Cerner Healthcare Solutions 17ME061Document14 pagesSmart HealthCare by Cerner Healthcare Solutions 17ME061NPMYS23No ratings yet
- Chapters - Perkins 2800 Workshop Manual (Page 2) - ManualsLibDocument1 pageChapters - Perkins 2800 Workshop Manual (Page 2) - ManualsLibHassan Eltayeb100% (1)
- Chevening Leadership Essay Sample by Obazure Ozil: Essaysers. EssaysersDocument3 pagesChevening Leadership Essay Sample by Obazure Ozil: Essaysers. Essaysersbesong100% (1)
- Finger Print AttendanceDocument65 pagesFinger Print Attendanceshanmugaraja85No ratings yet
- MSC Management With Data AnalyticsDocument3 pagesMSC Management With Data AnalyticsNishaNo ratings yet
- Matias Milio: Skills Work ExperienceDocument1 pageMatias Milio: Skills Work ExperienceAndrea DiggitaloNo ratings yet
- ზოგადად ქსელების შესახებDocument50 pagesზოგადად ქსელების შესახებFdfdd FsdfasdNo ratings yet
- 10 - Chapter 3 Security in M CommerceDocument39 pages10 - Chapter 3 Security in M CommercehariharankalyanNo ratings yet
- Alloy Module, S1 TITAN and Tracer 5iDocument15 pagesAlloy Module, S1 TITAN and Tracer 5iWoodrow FoxNo ratings yet
- Past Simple Negative Free Worksheet Live WorksheetsDocument1 pagePast Simple Negative Free Worksheet Live Worksheetsverasof20No ratings yet
- 7010 Computer Studies: MARK SCHEME For The May/June 2007 Question PaperDocument12 pages7010 Computer Studies: MARK SCHEME For The May/June 2007 Question PaperMuhammad MuddassirNo ratings yet
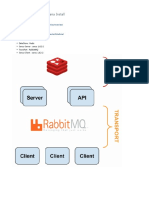
- Sensu + Graphite + Grafana Monitoring InstallationDocument16 pagesSensu + Graphite + Grafana Monitoring Installationfree4itvnNo ratings yet
- Digital Habits Acrossgenerations: Before ReadingDocument3 pagesDigital Habits Acrossgenerations: Before ReadingI Made Indra DananjayaNo ratings yet
- GLI-19 - V2.0 Interactive Gaming Systems PDFDocument100 pagesGLI-19 - V2.0 Interactive Gaming Systems PDFMárcio RamosNo ratings yet
- Multimedia Integration Formats ApplicationsDocument6 pagesMultimedia Integration Formats Applicationsvikashisur100% (1)
- Akuvox S567W Datasheet 190917 V2.0Document2 pagesAkuvox S567W Datasheet 190917 V2.0m.hatemNo ratings yet
- Online Examination 2021 - WT - FinalDocument2 pagesOnline Examination 2021 - WT - FinalarchchayaNo ratings yet
- Web Services Support InteractionsDocument19 pagesWeb Services Support InteractionsArsenia DuldulaoNo ratings yet
- CC Token 2.0white PaperDocument56 pagesCC Token 2.0white PaperBen LouisNo ratings yet
- Acer Download Tool User ManualDocument9 pagesAcer Download Tool User Manualursub_2No ratings yet
- MVC ArchitectureDocument50 pagesMVC ArchitectureskakachNo ratings yet
- Configuring Network ConnectivityDocument26 pagesConfiguring Network ConnectivityangelitoNo ratings yet
- 5 Communication and Network Concepts - QuestDocument17 pages5 Communication and Network Concepts - Questsarvesh guptaNo ratings yet
- 2022 FE RoadmapDocument4 pages2022 FE RoadmapAnil DangeNo ratings yet
- Warm Up (9/30) : - Why Should Someone Be Upset If Their Wallet Is Stolen or Lost?Document49 pagesWarm Up (9/30) : - Why Should Someone Be Upset If Their Wallet Is Stolen or Lost?Sandyz528No ratings yet
- Versatile Developer with Experience in ML and Web DevelopmentDocument1 pageVersatile Developer with Experience in ML and Web DevelopmentAyush ShahNo ratings yet
- Prime Infrastructure 2-1 v1-1 Demo ScriptDocument23 pagesPrime Infrastructure 2-1 v1-1 Demo Scriptoc3stm1No ratings yet
- E-Tutorial - Online Correction - Pay 220I, LP, LD, Interest, Late Filing, LevyDocument38 pagesE-Tutorial - Online Correction - Pay 220I, LP, LD, Interest, Late Filing, LevyPrasad IyengarNo ratings yet
- Janitza-Main catalogue-2015-ENDocument418 pagesJanitza-Main catalogue-2015-ENOchoa Para La BandaNo ratings yet
- Big Data Engineer Resume TemplateDocument2 pagesBig Data Engineer Resume Templateshreya arunNo ratings yet