You might also like
- An OvaDocument82 pagesAn OvaGargi RajvanshiNo ratings yet
- Analysis of VarianceDocument82 pagesAnalysis of VarianceshilpeekumariNo ratings yet
- An OvaDocument82 pagesAn OvaShweta SinghNo ratings yet
- Anova: Samprit ChakrabartiDocument30 pagesAnova: Samprit Chakrabarti42040No ratings yet
- Statistics For Business and Economics: Bab 13Document44 pagesStatistics For Business and Economics: Bab 13baloNo ratings yet
- ANOVA Marketing Strategy Sales AnalysisDocument53 pagesANOVA Marketing Strategy Sales AnalysisDivya LekhaNo ratings yet
- Anova: Analysis of VarianceDocument45 pagesAnova: Analysis of VarianceElizabeth JohnnyNo ratings yet
- 11-Anova For BRMDocument39 pages11-Anova For BRMabhdonNo ratings yet
- ANOVA DasarDocument37 pagesANOVA DasarekoefendiNo ratings yet
- ANOVA Analysis of VarianceDocument26 pagesANOVA Analysis of VarianceRishabh sharmaNo ratings yet
- MAS202 Chapter 11Document31 pagesMAS202 Chapter 11xuantoan501No ratings yet
- Analyze Variance with One-Way and Two-Way ANOVADocument19 pagesAnalyze Variance with One-Way and Two-Way ANOVALabiz Saroni Zida0% (1)
- ANOVA Reveals Differences in Car SafetyDocument6 pagesANOVA Reveals Differences in Car SafetyLuis ValensNo ratings yet
- Advanced Statistics: Analysis of Variance (ANOVA) Dr. P.K.Viswanathan (Professor Analytics)Document19 pagesAdvanced Statistics: Analysis of Variance (ANOVA) Dr. P.K.Viswanathan (Professor Analytics)vishnuvkNo ratings yet
- ANOVA Analysis Reveals Variance in Sample MeansDocument5 pagesANOVA Analysis Reveals Variance in Sample MeansAisha FarooqNo ratings yet
- AnovaDocument55 pagesAnovaFiona Fernandes67% (3)
- Distribution of Sample Means: Central Limit TheoremDocument11 pagesDistribution of Sample Means: Central Limit TheoremKuldeep BhattacharjeeNo ratings yet
- Advanced Statistics: Analysis of Variance (ANOVA) Dr. P.K.Viswanathan (Professor Analytics)Document19 pagesAdvanced Statistics: Analysis of Variance (ANOVA) Dr. P.K.Viswanathan (Professor Analytics)BaraniNo ratings yet
- Analysis of Variance PPT at BEC DOMSDocument56 pagesAnalysis of Variance PPT at BEC DOMSBabasab Patil (Karrisatte)100% (1)
- Chapter 6: Introduction To Analysis of Variance, Statistical Quality Control and System ReliabilityDocument14 pagesChapter 6: Introduction To Analysis of Variance, Statistical Quality Control and System ReliabilitySrinyanavel ஸ்ரீஞானவேல்No ratings yet
- 2 Mean Median Mode VarianceDocument29 pages2 Mean Median Mode VarianceBonita Mdoda-ArmstrongNo ratings yet
- Isom 2500Document58 pagesIsom 2500JessicaLiNo ratings yet
- Analysis of Variance (Anova)Document29 pagesAnalysis of Variance (Anova)aksabhishek88No ratings yet
- Chapter 3 Lesson 1Document54 pagesChapter 3 Lesson 1Doroty Castro83% (6)
- Analysis of VarianceDocument62 pagesAnalysis of VarianceJohnasse Sebastian NavalNo ratings yet
- S11 SPDocument15 pagesS11 SPSaagar KarandeNo ratings yet
- Bus173 Chap03Document42 pagesBus173 Chap03KaziRafiNo ratings yet
- Lec 1Document54 pagesLec 1Jayveer SinghNo ratings yet
- Analysis of Varience-One Way Analysis (Original Slide)Document25 pagesAnalysis of Varience-One Way Analysis (Original Slide)Hilmi DahariNo ratings yet
- Lecture 3Document7 pagesLecture 3Nhi TuyếtNo ratings yet
- Practice An OvaDocument11 pagesPractice An OvaHashma KhanNo ratings yet
- Module 11Document52 pagesModule 11Tanvi DeshmukhNo ratings yet
- WelcomeDocument19 pagesWelcomeSharath sharuNo ratings yet
- 04 Simple AnovaDocument9 pages04 Simple AnovaShashi KapoorNo ratings yet
- 12 AnovaDocument43 pages12 AnovaBeing VikramNo ratings yet
- ANOVA Module: Key Concepts and ApplicationsDocument17 pagesANOVA Module: Key Concepts and ApplicationsVarun BhayanaNo ratings yet
- IMP Video ConceptDocument56 pagesIMP Video ConceptParthJainNo ratings yet
- THESIS Consolidated ReportDocument102 pagesTHESIS Consolidated ReportNoruel Jan Galvadores MiguelNo ratings yet
- Chi-Square, F-Tests & Analysis of Variance (Anova)Document37 pagesChi-Square, F-Tests & Analysis of Variance (Anova)MohamedKijazyNo ratings yet
- Statistics For Decision Making: ANOVA: Analysis of VarianceDocument32 pagesStatistics For Decision Making: ANOVA: Analysis of VarianceAmit AdmuneNo ratings yet
- ANo VADocument56 pagesANo VATeja Prakash chowdary100% (3)
- Error and Uncertainty: General Statistical PrinciplesDocument8 pagesError and Uncertainty: General Statistical Principlesdéborah_rosalesNo ratings yet
- Stat Slides 5Document30 pagesStat Slides 5Naqeeb Ullah KhanNo ratings yet
- AnovaDocument105 pagesAnovaasdasdas asdasdasdsadsasddssaNo ratings yet
- Analysis of VarianceDocument15 pagesAnalysis of VarianceSenelwa AnayaNo ratings yet
- Tatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialDocument15 pagesTatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialPrima JoeNo ratings yet
- One and Two Way ANOVADocument11 pagesOne and Two Way ANOVADave MillingtonNo ratings yet
- PPT08 - Analysis of VarianceDocument45 pagesPPT08 - Analysis of VarianceAmalia KNNo ratings yet
- Probability Distribution DiscreteDocument16 pagesProbability Distribution Discretescropian 9997No ratings yet
- Forecasting Cable Subscriber Numbers with Multiple RegressionDocument100 pagesForecasting Cable Subscriber Numbers with Multiple RegressionNilton de SousaNo ratings yet
- Presentation 6Document43 pagesPresentation 6Swaroop Ranjan BagharNo ratings yet
- AnovaDocument46 pagesAnovasampritcNo ratings yet
- Stat 3Document42 pagesStat 3Al Arafat RummanNo ratings yet
- Acc QMDocument15 pagesAcc QMTomoki HattoriNo ratings yet
- Lecture 5 - 2 - 2015 - Sampling Distn - FINAL - Complete Version PDFDocument40 pagesLecture 5 - 2 - 2015 - Sampling Distn - FINAL - Complete Version PDFJugal BhojakNo ratings yet
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignFrom EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNo ratings yet
- Statistical Inference in Financial and Insurance Mathematics with RFrom EverandStatistical Inference in Financial and Insurance Mathematics with RNo ratings yet
- Capacity CalculationDocument13 pagesCapacity CalculationPradeepNo ratings yet
- Capacity CalculationDocument13 pagesCapacity CalculationPradeepNo ratings yet
- KPS: Teori ConstraintDocument10 pagesKPS: Teori ConstraintPaRaDoX eLaKSaMaNaNo ratings yet
- JITfinalDocument32 pagesJITfinalPradeepNo ratings yet
- Statistical Tests PDFDocument7 pagesStatistical Tests PDFPradeepNo ratings yet
- Quality GuruDocument53 pagesQuality Gurutehky63No ratings yet
- LR Guide: Key Concepts for Logistic Regression ModelsDocument29 pagesLR Guide: Key Concepts for Logistic Regression ModelsPradeepNo ratings yet
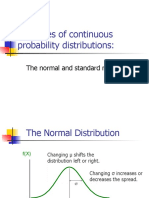
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument58 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalupasanamohantyNo ratings yet
- JITfinalDocument32 pagesJITfinalPradeepNo ratings yet
- Thread Scheduling and DispatchingDocument75 pagesThread Scheduling and DispatchingPradeepNo ratings yet
- IMS Partners with JSTOR to Preserve Annals of Math StatsDocument12 pagesIMS Partners with JSTOR to Preserve Annals of Math StatsPradeepNo ratings yet
- Lecture 4Document45 pagesLecture 4PradeepNo ratings yet
- Conditional RegressionDocument7 pagesConditional RegressionPradeepNo ratings yet
- Logistic Regression Predicts Binge Drinking from Facebook UseDocument28 pagesLogistic Regression Predicts Binge Drinking from Facebook UsePradeepNo ratings yet
- S Tatistical Tolerance Synthesis Using Distribution Function ZonesDocument12 pagesS Tatistical Tolerance Synthesis Using Distribution Function ZonesPradeepNo ratings yet
- Mantel-Haenszel Test1Document1 pageMantel-Haenszel Test1PradeepNo ratings yet
- ANOVA701Document55 pagesANOVA701PradeepNo ratings yet
- Lecture 4Document45 pagesLecture 4PradeepNo ratings yet
- ANOVA701Document55 pagesANOVA701PradeepNo ratings yet
- Wiley Finance Art of Company Valuation and Financial Statement Analysis A Value Investor S Guide With Real Life Case StudiesDocument4 pagesWiley Finance Art of Company Valuation and Financial Statement Analysis A Value Investor S Guide With Real Life Case StudiesPradeepNo ratings yet
- 19741Document4 pages19741pkj009No ratings yet
- 1209876Document7 pages1209876PradeepNo ratings yet
- Buffetts First BillionDocument35 pagesBuffetts First Billionbhaskar.jain20021814No ratings yet
- 76754Document9 pages76754pkj009No ratings yet
- Building Good Models Is Not Enough: Richard RichelsDocument8 pagesBuilding Good Models Is Not Enough: Richard RichelsPradeepNo ratings yet
- Aggregate Planning With Learning Curve Productivity : BackgroundDocument13 pagesAggregate Planning With Learning Curve Productivity : BackgroundPradeepNo ratings yet
- Graham 1Document5 pagesGraham 1SANUNo ratings yet
- SharemarketDocument7 pagesSharemarketerganeshNo ratings yet
- 171473Document10 pages171473PradeepNo ratings yet
- 171820Document12 pages171820PradeepNo ratings yet
- Rule #1 Explained: 2.7.1 Variations of Form (Rule #1: Envelope Principle)Document6 pagesRule #1 Explained: 2.7.1 Variations of Form (Rule #1: Envelope Principle)Anonymous 7ZTcBnNo ratings yet
- MATH Final Exam Review SheetDocument6 pagesMATH Final Exam Review SheetEbrahim ShahidNo ratings yet
- Oo Abap DeclarationsDocument15 pagesOo Abap DeclarationsvenkatNo ratings yet
- Tower of Hanoi Micro ProjectDocument27 pagesTower of Hanoi Micro ProjectRusherz WØLFNo ratings yet
- Mmw-Unit 1Document7 pagesMmw-Unit 1Ella DimlaNo ratings yet
- Real Analysis Lecture SldiesDocument16 pagesReal Analysis Lecture Sldiesruchi21july100% (1)
- Panjaitan & Sarah (2023) - Adaptasi Career Adapt-Abilities - Short Form Ke Versi Indonesia PDFDocument11 pagesPanjaitan & Sarah (2023) - Adaptasi Career Adapt-Abilities - Short Form Ke Versi Indonesia PDFEliasFundiceNo ratings yet
- Bearing Capacity of Shallow Foundation PDFDocument20 pagesBearing Capacity of Shallow Foundation PDFAbera MulugetaNo ratings yet
- TL Glaiza Alair - Sultan KudaratDocument64 pagesTL Glaiza Alair - Sultan Kudaratleon08jayNo ratings yet
- DSP Lab Expt 3 EECE GITAM-19-23Document5 pagesDSP Lab Expt 3 EECE GITAM-19-23gowri thumburNo ratings yet
- Sankalp Monthly Test Notice Class 12Document2 pagesSankalp Monthly Test Notice Class 12rakeshNo ratings yet
- Hanouts Sta304Document191 pagesHanouts Sta304silence queenNo ratings yet
- Programming Fundamentals Assignment SolutionsDocument10 pagesProgramming Fundamentals Assignment Solutionsali anwarNo ratings yet
- TrinMaC Virtual Winter 2022 HS ProblemsDocument5 pagesTrinMaC Virtual Winter 2022 HS ProblemsbogdanNo ratings yet
- Handbook of Transport GeographyDocument17 pagesHandbook of Transport GeographyAnil Marsani100% (1)
- Generator Answers 3Document6 pagesGenerator Answers 3Ahmad SwandiNo ratings yet
- Break and Continue MCQ AnsDocument11 pagesBreak and Continue MCQ Ansnancy_007No ratings yet
- Design Principles MatrixDocument1 pageDesign Principles MatrixArch. Jan EchiverriNo ratings yet
- Mathematics of Cryptography: Algebraic StructuresDocument68 pagesMathematics of Cryptography: Algebraic StructuresSrivathsala Suresh TangiralaNo ratings yet
- Rotational Equilibrium and Rotational DynamicsDocument12 pagesRotational Equilibrium and Rotational DynamicsCG AmonNo ratings yet
- Syllabus STAB52 F20 LEC01Document4 pagesSyllabus STAB52 F20 LEC01rickyangnwNo ratings yet
- Convex FunctionsDocument93 pagesConvex FunctionsAntonio Villagómez ChiluisaNo ratings yet
- Arm Exercises For LabDocument3 pagesArm Exercises For Labnizamhaider123No ratings yet
- notesSDE PDFDocument124 pagesnotesSDE PDFxkzffqmzkxNo ratings yet
- HR Demand ForecastingDocument27 pagesHR Demand ForecastingSarathBabuNo ratings yet
- Decision Making by AHP and ANPDocument51 pagesDecision Making by AHP and ANPRahmat M JayaatmadjaNo ratings yet
- Engineering Graphics Assignment Long Questions Unit-IDocument2 pagesEngineering Graphics Assignment Long Questions Unit-Ishaikamaan10jgs18080006No ratings yet
- Vimal's ResumeDocument3 pagesVimal's Resumevimaljss91No ratings yet
- Basic Concepts of Differential and Integral CalculusDocument6 pagesBasic Concepts of Differential and Integral CalculusManoj KhandelwalNo ratings yet
- Stress6 ht08 2Document26 pagesStress6 ht08 2fredrikalloNo ratings yet